이번 포스팅은 RealMySQL8.0의 트랜잭션과 잠금에 대해서 정리하는 글을 작성하도록 하겠습니다.!
1. MySQL 엔진의 잠금
MySQL에서 사용되는 잠금은 스토리지 엔진 레벨과 MySQL 엔진 레벨로 나뉩니다.
MySQL 엔진 레벨의 잠금은 스토리지 엔진 레벨 잠금에 영향을 줄 수 있습니다.
MySQL 엔젠 레벨은 클라이언트로부터 쿼리를 받아 처리하고 결과를 반환하는 등 클라이언트에게 직접적인 엔진 레벨이지만, 스토리지 엔진 레벨은 DB 저장 및 검색 관리 방식 등을 결정하는 엔진으로 디스크에 가까운 역할을 수행하고 있습니다.
2. 글로벌 락
글로벌락은 다음과 같은 명령으로 획득할 수 있습니다. MySQL에서 제공하는 잠금 중 가장 큰 범위로 select를 제외한 대부분의 DDL 혹은 DML 문장을 실행하는 경우 글로벌 락이 해제될 때까지 해당 문장이 대기 상태로 남습니다.
FLUSH TABLES WITH READ LOCK
FLUSH TABLES WITH READ LOCK은 테이블에 읽기 잠금을 걸기 전에 먼저 테이블을 플러시 해야 하므로 테이블에 실행 중인 모든 종류의 쿼리가 완료되어야 합니다.
3. 백업 락
MySQL8.0 버전부터는 XtraBackup 혹은 Enterprise Backup과 같은 백업 툴들의 안정적인 실행을 위해 백업 락이 도입되었습니다.
XtraBackup: 오픈 소스로 도입되는 InnoDB 스토리지 엔진 전용의 무료 백업 도구로 물리적인 백업 방식을 사용합니다. XtraBackup은 인크리멘탈 백업 파일을 사용하는데, 이는 마지막 전체 백업 이후 변경된 데이터만 백업하는 방법을 의미합니다. 따라서 백업 파일의 크기를 줄이고 백업 속도를 향상할 수 있습니다.
Enterprise Backup은 기업용 백업 솔루션으로 별도의 백업 서버에서 실행됩니다.
백업 락의 실행 과정이 잘 이해가 안되는 부분이 있어서 제가 이해한 바를 하단에 정리하였는데 이 부분은 실제 내용과 다를 수 있습니다.!
소스 서버에 있는 데이터를 백업하기 위해 레플리카 서버가 활용되는데, 백업을 위해 소스 서버 전체를 글로벌 락으로 잠그는 데에는 효율적이지 않습니다.
일반적으로 백업하는 과정에서 DDL 요청이 수행되면 백업에 실패하게 됩니다.
이러한 문제를 해결하기 위해 레플리카 서버에 백업 락을 설정하여 소스 서버는 DDL이 처리될 때 레플리카 서버는 잠시 DDL 처리가 완료되기까지 락을 해제하고 대기합니다. DDL이 종료되면 백업을 진행하게 됩니다.
4. 테이블 락
테이블 락은 명시적 또는 묵시적 락으로 특정 테이블의 락을 획득할 수 있습니다.
명시적으로 획득한 잠금은 잠금을 반납할 수 잇는데, 특별한 상황이 아니라면 사용할 일이 많이 없습니다.
반면, 묵시적 테이블 락은 MyISAM 혹은 MEMORY 테이블에 데이터를 변경하는 쿼리를 실행하면 발생합니다.
InnoDB 엔진에서는 테이블 락이 설정되기는 하지만 DML 쿼리에서는 레코드 락이 설정되고 DDL의 경우 영향을 미칩니다.
5. 네임드 락
네임드락은 GET_LOCK() 함수를 이용해 임의의 문자열에 대한 잠금을 설정하비다.
네임드 락은 단순히 사용자가 지정한 문자열에 대해 획득하고 반납하는 잠금입니다. 이러한 잠금으로 동일한 요청에 대한 반복 수행 등을 방지하는 역할을 수행할 수 있습니다.
네임드 락은 분산락과 비슷하지만 다른 용도로 사용됩니다.
네임드 락
분산 락
문자열(키)로 잠금
문자열(키)로 잠금
공유 자원 접근을 관리하되, 단일 데이터베이스에서 상호 동기화 처리에 용이
여러 데이터베이스 클러스터간 공유 자원 접근을 제어
6. InnoDB 스토리지 엔진 잠금
InnoDB 스토리지 엔진은 레코드 기반의 잠금 기능을 제공하며, 잠금 정보가 상당히 작은 공간으로 관리되기 때문에 레코드 락이 페이지 락으로 또는 테이블 락으로 레벨업 되는 경우는 없습니다.
InnoDB 스토리지 엔진은 레코드 락과 갭 락, 넥스트 키 락을 제공합니다.
사실 이 부분은 명확하게 이해하기가 너무 어려웠습니다. 따라서 먼저 이론적인 내용을 정리한 후, 실습을 통해 제가 이해한 바를 정리하도록 하겠습니다 (이 부분 역시 사실과 다를 수 있는 점 양해 부탁드립니다.)
<레코드 락>
레코드 자체를 잠그는 것을 레코드 락이라고 합니다. InnoDB 스토리지 엔진은 레코드 자체가 아니라 인덱스의 레코드를 잠급니다.
인덱스가 없는 경우 자동 생성된 클러스터 인덱스를 이용해 잠금을 처리합니다.
<갭 락>
갭 락은 레코드 자체가 아니라 레코드와 바로 인접한 레코드 사이의 간격만을 잠그는 것을 의미합니다.
갭 락의 역할은 레코드와 레코드 사이의 간격에 새로운 레코드가 생성되는 것을 제어합니다.
<넥스트 키 락>
레코드 락과 갭 락을 합쳐 놓은 형태로 innodb_locks_unsafe_for_binlog 시스템 변수가 비활성화되면 변경을 위해 검색하는 레코드에는 넥스트 키 락 방식으로 잠금이 걸립니다.
<실습>
먼저, 실습 환경은 MySQL8.25 REPEATABLE READ 격리 수준입니다.
주어진 테이블의 인덱스를 확인하기 위해 아래의 명령어를 작성하여 프라이머리 키와 보조 인덱스를 확인하였습니다.
show index from employees;
이후, insert into 구문으로 새로운 데이터 2 개를 삽입하였습니다.
보조 인덱스로 검색할 경우, 보조 인덱스가 잘 적용되는지 확인하기 위해 실행 계획을 실행한 결과 올바르게 적용되었습니다.
먼저 1번 터미널에 start transaction을 작성하고, 2번 터미널에서도 start transaction을 적용하여 서로 격리된 트랜잭션을 적용하였습니다.
이 상태로, 1번 터미널에서 성별이 M이고 1997-01-01과 1997-01-03 사이에 업데이트를 위한 조회문을 작성하였습니다.
select * from employees where gender = 'M' and birth_date between '1997-01-01' and '1997-01-03' for update;
2번 터미널에서는 1997-01-02과 1997-01-03 사이인 1997-01-02일 값을 가지는 인서트문을 작성하였습니다.
그 결과, 프라이머리키로 범위를 설정하였을 때도 갭 락이 적용되는 것을 확인할 수 있었습니다.
교재나 다른 글에서는 프라이머리 키 또는 유니크 인덱스에 의한 변경 작업에서 갭에 대해서는 잠그지 않고 레코드 자체에 대해서만 잠근다고 설명되어 있습니다.
현재, LOCK_MODE에 GAP이 있지만 이 것이 어떠한 이유로 적용되었는지는 파악하기가 어려웠습니다. 제가 이해한 바로는 프라이머리 키 또는 유니크 인덱스에 의한 변경 작업은 직접적으로 pk를 이용하여 변경하므로 갭을 사용하지 않지만 위의 예시와 같이 범위를 설정하는 경우에는 갭락이 적용되는 것이라고 생각하게 되었습니다.
데이터베이스를 얕게 알 때는 몰랐지만, 공부를 하면 할수록 정말 어려운 것 같습니다.
락에 대해서 전 보다 깊게 배울 수 있었고 어떤 상황에는 어떠한 락이 적용되는지 파악할 수 있었습니다.
이번 포스팅은 운영체제의 메모리 관리에 대한 글을 작성하고자 합니다. 먼저 가상 메모리의 경우 분량이 방대하기 때문에 다음 포스팅에 작성하고, 기본적인 메모리 방식을 위주로 정리하도록 하겠습니다.
멀티프로그래밍 시스템에서 효과적인 메모리 관리는 필수적입니다. 적은 수의 프로세스만이 주기억장치에 있을 때, 대부분의 시간 동안 입출력 작업 종료를 기다리게 되고 처리기는 아무 일도 하지 않게 됩니다. 따라서, 메모리는 사용 가능한 처리기 시간을 소비하기에 충분한 수의 프로세스들이 준비 상태에 있도록 할당되어야 합니다.
1. 메모리 관리 요구조건
재배치 - 프로세스가 디스크로 스왑아웃이 되면, 스왑인이 될 때, 다른 공간으로 프로세스를 재배치해야 합니다. 이 과정에서 메모리 참조 부분을 실제 물리주소로 변환할 수 있어야 합니다.
보호 - 다른 프로세스에 속한 프로그램들은 허가 없이 읽기나 쓰기를 위해 임의의 프로세스의 메모리를 참조하면 안 됩니다.
공유 - 필수적인 보호 기능을 침해하지 않는 범위에서 제한된 접근을 통하여 메모리의 일부분을 공유할 수 있도록 허용해야 합니다.
2. 메모리 관리 기법
메모리 관리의 주된 작업은 처리기에 의해 실행될 프로세스를 주기억 장치로 가져오는 것입니다. 주로 '세그먼테이션'과 '페이징'을 활용하는 가상 메모리가 사용되고 있습니다.
기술
설명
장점
단점
고정 분할
시스템 생성 시에 주기억장치가 고정된 파티션들로 분할
프로세스는 균등 사이즈의 파티션 또는 그보다 큰 파티션으로 적재
구현 간단 (운영체제 오버헤드 거의 X)
내부 단편화 발생 최대 활성 프로세스 수 고정
동적 분할
파티션들이 동적으로 생성 각 프로세스는 자신의 크기와 일치하는 크기의 파티션에 적재
내부단편화 X
외부 단편화 발생 메모리 집약으로 인한 효율 하락
단순 페이징
주기억장치는 균등 사이즈 프레임으로 나뉨
프로세스는 프레임들과 같은 길이를 가진 균등페이지들로 나뉨
프로세스의 모든 페이지가 적재되어야 하고 이 페이지를 저장하는 프레임은 비연속 가능
외부 단편화 X
적은 양의 내부 단편화 발생
단순 세그먼테이션
각 프로세스는 여러 세그먼트들로 분할 프로세스의 모든 세그먼트 적재 세그먼트를 저장하는 동적 파티션들은 비연속 가능
내부 단편화 X 동적 분할에 비해 오버해드 적음
외부 단편화 발생
가상 메모리 페이징
프로세스 페이지를 한 번에 전부 로드 X 필요한 페이지가 있으면 후에 호출
외부 단편화 X 멀티 프로그래밍 정도 높음 가상 주소 공간 큼
복잡한 메모리 관리와 오버헤드
가상 메모리 세그먼테이션
필요하지 않은 세그먼트들 로드 X 필요하면 후에 호출
내부 단편화 X 멀티 프로그래밍 정도 높음 큰 가상 주소 공간
복잡한 메모리 관리와 오버헤드
3. 고정 분할
주기억장치를 관리하는 가장 단순한 기법은 고정된 경계를 가지는 메모리 영역으로 구분합니다.
분할크기: 각 분할이 고정된 경계를 가지는 메모리 영역으로 구분되며 균등 분할과 비균등 분할로 나뉩니다.
프로그램이 파티션보다 클 수 있다는 단점이 있습니다 또한, 매우 적은 메모리를 필요로 하더라도 고정된 파티션의 일부에 적재되어야 하기 때문에 내부 공간의 낭비가 발생하는 내부 단편화가 발생합니다.
배치 알고리즘은 균등 분할의 경우 모두 동일한 크기의 파티션으로 균등 분할 되어 있으므로 적재 가능한 파티션이 하나라도 존재하면 프로세스는 배치가 가능합니다.
비균등 분할의 경우 각 프로세스의 용량에 맞는 가장 작은 파티션을 할당하기 위해 스왑아웃된 프로세스들을 유지하는 스케줄링 큐가 필요합니다.
4. 동적 분할
고정 분할의 기법에서 발생하는 몇 가지 문제점을 해결하기 위해 동적 분할 기법이 개발되었지만 이 기술 역시 현재는 잘 쓰이지 않습니다.
동적 분할에서 파티션의 크기와 개수는 가변적입니다. 한 프로세스가 주기억장치로 적재될 때, 정확히 요구된 크기만큼의 메모리만 할당받습니다.
서로 다룬 프로세스가 스왑인 스왑아웃 하는 과정에서 주기억장치에 사용할 수 없는 단편화된 구멍이 생기게 되는데, 이러한 조각화된 메모리를 외부 단편화라 부릅니다. 이는 메모리 효율성을 저하시킵니다.
메모리 집약을 사용할 경우 파티션을 연속적이게 인접하도록 만들 수 있지만 불필요한 재배치 시간이 소모됩니다.
그림1
배치 알고리즘으로 최적적합, 최초적합, 순환적합 종류가 있으며 최초적합은 가장 간단하며 대부분 가장 최적입니다. 순환 적합은 메모리 마지막 부분에 있는 사용 가능한 블록에서 자주 일어나고, 최적적합은 이름과 다르게 가장 성능이 나쁜 방법으로 가장 작은 블록을 찾아 배정하므로 가장 작은 외부 단편화를 생성합니다.
5. 버디 시스템
그림2
버디 시스템은 2^k로 블록 단위로 할당 가능한 메모리에 따라 블록을 나눌 수 있습니다. 그림과 같이 만약 56K의 메모리가 필요할 경우 256K -> [128K, 128K] -> [128K, [64K, 64K]]로 나누며 가장 작은 단위에 프로세스를 적재하는 방식입니다.
6. 재배치
프로세스가 스왑인 스왑아웃되는 과정에서 데이터 위치가 변경될 수 있습니다. 이 문제를 해결하기 위해 주소 유형을 정의하여 적절한 조치 및 변환이 이루어져야 합니다.
논리주소: 현재 데이터가 적재된 메모리와는 독립적인 메모리 위치에 대한 참조입니다. 반드시 물리주소로 변환되어야 합니다.
상대주소: 어떤 알려진 시점, 주로 처리기의 한 레지스터 값으로부터 상대적인 위치를 의미합니다.
물리주소: 절대주소란 주기억장치 안에서의 실제 위치를 의미합니다.
재배치를 지원하는 하드웨어의 경우 프로세스가 실행 상태가 될 때, '베이스 레지스터'에 프로세스의 주기억장치의 시작주소가 적재됩니다. 프로세스를 실행하는 동안은 상대주소가 사용되며, 베이스 레지스터로 상대주소에 베이스 레지스터에 적재된 값이 더해져 절대주소로 변환되어 사용됩니다.
7. 페이징
주기억장치를 비교적 작은 고정 사이즈 파티션으로 나누고(프레임) 각 프로세스 또한 같은 크기의 고정 조각(페이지)으로 나눌 수 있습니다. 따라서, 외부 단편화에 대한 낭비를 없애고, 내부 단편화의 경우 마지막 페이지에서만 발생하도록 처리할 수 있습니다.
이 경우, 만약 각 프로세스들이 스왑인 스왑아웃 되는 과정에서 비연속적인 공간이 발생할 수 있습니다. 하지만 논리주소와 '페이지 테이블'을 통해 프로세스의 각 페이지들에 해당하는 프레임의 위치를 관리하여 비연속적인 공간에 단편화된 프레임을 점유하도록 함으로써 내부 단편화를 없앨 수 있습니다.
페이지 테이블은 프로세스의 각 페이지들에 해당하는 프레임의 위치를 관리합니다.
각 논리주소는 페이지 번호와 페이지 내의 오프셋으로 구성됩니다.
논리주소(페이지 번호, 오프셋)가 주어지면 처리기는 페이지 테이블을 이용하여 물리주소(프레임 숫자, 오프셋)를 생성합니다.
페이징과 오프셋은 시스템 아키텍처와 메모리 관리 전략에 따라 다를 수 있습니다.
만약 가상 주소 공간이 32비트이고 페이지당 4KB라면, 페이지 번호와 오프셋으로 나뉘게 됩니다.
20비트: 페이지 번호 (1024byte * 4 = 4096KB)
12비트: 오프셋 (2^12 = 4096)
총 오프셋 개수 : 2^20 * 2^12 = 2^32
8. 세그먼테이션
세그먼테이션은 페이지 번호와 오프셋을 사용하는 것은 동일하지만, 페이징과 달리, 메모리 관리가 가변적입니다. 세그멘테이션은 논리적인 메모리 구조를 지원하므로 프로그램의 모듈화가 용이하지만, 외부 단편화 문제가 발생할 수 있습니다.
>> 외부 단편화가 발생하는 이유는 메모리 공간이 가변적이기 때문에 스왑아웃되어 다른 프로세스가 메모리 공간을 점유하려고 할 때 그 공간이 메모리 요구조건을 만족시키지 않을 가능성이 높기 때문입니다.
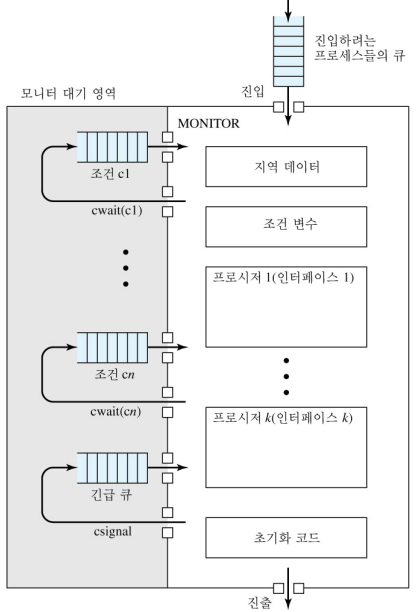
이번 포스팅은 상호 배제의 방법으로 Hoare(토니 호어)의 모니터 방식과 Lampson/Redell의 모니터 방식을 정리하도록 하겠습니다.
이전 포스팅은 운영체제에서 공유 자원의 상호 배제 방법으로 세미포어를 활용하는 것을 정리하였습니다. 세미포어는 상호 배제 보장과 프로세스 간 협력을 위해 사용되는 강력하고 유연한 프리미티브이지만, 구현하기가 어렵고 모듈화가 되지 않는다는 단점이 있습니다. 이러한 문제를 해결하기 위한 방법으로 '토니 호어'가 '모니터'를 제안하였습니다.
1. 모니터
모니터는 프로그래밍 언어 수준에서 제공되는 구성체로 세마포어와 동일한 기능을 제공합니다. 모니터에 대한 개념은 Concurrent Pascal, Java 등 다양한 언어로 구현되어 있습니다.
Hoare가 제안한 시그널 기반 모니터
지역 변수는 모니터의 프로시저를 통해 접근 가능합니다. 즉, 외부에서 변수에 대한 직접 접근은 허용되지 않습니다.
프로세스는 모니터의 프로시저 중에 하나를 호출함으로써 모니터로 들어갑니다.
한 순간에 오직 하나의 프로세스만이 모니터 내에 존재할 수 있습니다. 즉, 모니터가 이미 사용 중인 경우 다른 프로세스들은 모니터가 이용 가능해질 때까지 대기해야 합니다. (상호 배제)
모니터는 동기화를 위해 조건 변수(condition variabls)를 제공합니다. 조건 변수는 모니터 내부에 포함되며, 모니터 내부에서만 접근할 수 있습니다.
cwait(c): 호출한 프로세스를 조건 c에서 일시 중지합니다. 모니터는 이제 다른 프로세스에서 사용될 수 있습니다.
csignal(c): cwait(c)에 의해 중지되었던 프로세스의 수행을 다시 재개시킵니다. 만일 중지된 프로세스가 여러 개일 경우 그 중하나를 선택합니다. 만약 중지된 프로세스가 없다면 시그널은 아무 일도 일어나지 않습니다.
2. 모니터 수행 과정
A 프로세스 지역 변수 x와 관련된 프로시저 호출
B 프로세스가 모니터 진입점에서 진입 시도
모니터를 프로세스 A가 이미 사용 중이므로 대기 큐[x]에 블록
프로세스가 지역 변수 x 관련 프로시저를 마친 경우 cSignal(x) 호출
이전에 중단된 프로세스C가 있다면 프로세스 블록 큐에서 호출하여 진행
사진 1
3. 기존 모니터 모델의 단점
cSignal을 호출한 프로세스가 호출 이후 여전히 해야 할 작업이 남아 있다면, 두 번의 추가적인 프로세스 문맥 교환이 필요합니다. 한 번은 호출한 프로세스를 일시중지 시키고, 모니터가 다시 사용하게 되었을 때, 재개시키기 위해 필요합니다.
스케줄러는 cSignal 호출로 인해 cWait() 중인 프로세스가 블록 큐에서 나와 실행되어 다른 프로세스가 모니터에 들어가지 않도록 해야 합니다. 만약 계속 새로운 프로세스가 모니터에 입장할 경우 블록 큐에 있는 프로세스는 계속 대기상태에 있을 수 있습니다.
저는 처음에 스케줄러는 cSignal 호출로 인해 cWait() 중인 프로세스가 블록 큐에서 나와 실행되어 다른 프로세스가 모니터에 들어가지 않도록 해야 하는 부분이 자세히 이해가 되지 않았습니다.
하지만 위에서 정리한 수행 과정에 하나의 예시를 더 추가해보고 생각해 보았더니 이해할 수 있었습니다.
자원 소비를 담당하는 프로세스 A 모니터 진입 -> 조건 a에 대해 cWait(a)로 모니터에서 나와 블록 큐로 이동
자원 소비를 담당하는 프로세스 C가 대기 큐에 모니터 진입 -> 조건 a에 대해 cWait(a)로 모니터에서 나와 블록 큐로 이동
현재 블록 큐 (A, C) 순서
자원 추가를 담당하는 프로세스 D가 대기 큐에서 모니터 진입 -> 조건 a를 만족하여 cSignal(a) 호출
대기 큐에 프로세스E가 있더라도 블록 큐에 있는 A를 모니터에 진입하여 cWait() 이후 과정을 수행할 수 있도록 수행
4. Lampson과 Redell의 모니터 모델
토니 호어의 모니터 모델의 단점을 극복하기 위해 Lampson과 Redell이 다른 모니터 모델을 개발하였습니다.
csignal() -> cnotify()로의 도입으로 각 조건 변수에 대한 최대 대기 시간을 설정할 수 있습니다.
주요 변경 로직은 if 로 설정된 조건을 while로 대체하는 소스입니다. while( count == N) cwait(notfull);
조건 변수에 감시 타이머를 설정하여 최대 대기 시간을 기다린 프로세스는 다시 준비 상태로 전이시킬 수 있습니다.
cbroadcast의 추가로 대기하고 있는 모든 프로세스를 전부 깨울 수 있습니다. 이 효과는 메모리 10이 확보되었을 때, 메모리에 충족하는 특정 프로세스만 실행시켜야 할 때, 전부 프로세스를 깨움으로써 가용한 프로세스를 수행시킬 수 있습니다.
이 부분에서 while()에 대한 이해되지 않는 부분이 생겼습니다. while 루프를 활용한다면 무한 루프에 빠지지 않을까라는 궁금증입니다. 하지만, 이 부분은 너무나 명쾌하게 해결할 수 있는 문제였습니다. 실제 블록 큐로 이동하게 된다면 큐에서 빠져나오지 않는 한 cpu에서 실행되지 않습니다. cnotify나 cbroadcast를 호출할 때 비로소 큐에서 빠져나와 할당받을 수 있으며 다시 while 루프에서 자원에 대한 조건을 처리하므로 안정적으로 자원에 대한 상호배제와 동기화를 처리할 수 있습니다.
프로세스 간에 시그널을 주고받기 위해 사용되는 정수 값으로, 세마포어는 3가지 원자적인 연산을 지원합니다. initialize, decrement, increment
decrement 연산은 프로세스를 블록 시킬 수 있습니다. 반면 increment 연산은 블록되었던 프로세스를 깨울 수 있습니다.
복잡한 프로세스 간 상호작용 속에서 세마포어 s를 통해 시그널을 전송하기 위해 프로세스는 semSignal(s)라는 프리미티브를 수행합니다.
반면, 세마포어 s를 통해 시그널을 수신하기 위해 프로세스는 semWait(s)라는 프리미티브를 수행합니다.
종류는 범용 세마포어, 이진 세마포어 등이 있습니다.
2. 세마포어 연산
세마포어 초기화: 세마포어는 음이 아닌값으로 초기화됩니다.
semWait 연산: 세마포어 값을 감소시킵니다. 만일 값이 음수가 되면, semWait를 호출한 프로세스는 블록됩니다. 음수가 아니면 프로세스는 계속 수행됩니다.
semSignal 연산: 세마포어 값을 증가시킵니다. 만약 값이 양수가 아니면 semWait 연산에 의해 블록된 프로세스를 깨웁니다.
3. 세마포어의 사용 예
세마포어는 여러 프로세스 또는 스레드가 공유 리소스에 동시 접근하는 것을 제어하는데 사용됩니다.
공유 메모리 : 여러 프로세스가 동시에 메모리에 접근할 때, 서로 읽기 쓰기 작업이 충돌하지 않도록 보장하기 위해 사용됩니다.
파일 시스템: 여러 프로세스가 동시에 파일이나 디렉토리에 접근할 때, 데이터 일관성을 유지하기 위해 사용됩니다.
프로세스간 통신: 여러 프로세스가 메세지를 전달하거나 데이터를 주고받을 때, 동기화를 위해 사용됩니다.
데이터베이스 시스템: 여러 사용자나 애플리케이션에서 동시에 데이터베이스에 접근할 때, 트랜잭션의 원자성과 일관성을 보장하기 위해 사용됩니다.
4. 세마포어 프리미티브
< 범용 세마포어 프리미티브 >
public class OsExample {
class GeneralSemaphore {
int count;
Queue<Pid> queue;
}
class Pid {
public Pid() {}
}
void semWait(GeneralSemaphore s) {
s.count--;
if (s.count < 0) {
/* 요청한 프로세스를 s.queue에 연결 */
/* 요청한 프로세스를 블록 상태로 전이시킴 */
}
}
void semSignal(GeneralSemaphore s) {
s.count++;
if (s.count <= 0) {
/* s.queue에 연결되어 있는 프로세스를 큐에서 제거 */
/* 프로세스 상태를 실행 가능으로 전이시키고 redy list에 연결 */
}
}
}
< 이진 세마포어 프리미티브 >
public class BinarySemaphoreEx {
class BinarySemaphore {
Value value;
Queue<Pid> queue;
}
class Pid {
public Pid() {}
}
void semWaitB(BinarySemaphore s) {
if (s.value == ONE) s.value = ZERO;
else {
/* 요청한 프로세스를 s.queue에 연결 */
/* 요청한 프로세스를 블록 상태로 전이 */
}
}
void semSignalB(BinarySemaphore s) {
if (s.queue.isEmpty()) s.value = ONE;
else {
/* s.queue에서 프로세스 p를 제거 */
/* 프로세스의 p의 상태를 실행 가능으로 전이, ready list에 연결 */
}
}
}
5. 세마포어 정책
범용 세마포어와 이진 세마포어 모두 세마포어에서 블록된 프로세스들을 관리하기 위해 큐를 사용합니다.
세마포어는 큐를 적용하는 정책에 따라 두 가지로 분리할 수 있습니다
강성 세마포어
프로세스들이 세마포어를 사용할 때, 먼저 semWait를 호출한 프로세스가 먼저 semSignal을 호출할 수 있는 순서로 실행됩니다.
즉, 강력한 선입선출을 유지하여 많은 OS에서 강성 세마포어를 주로 사용하고 있습니다.
<강성 세마포어 실행 순서>
프로세스 D 실행 s = 1 (S는 D가 실행되면 +1 )
D는 준비 큐 대기
A프로세스, B프로세스, D 준비 상태
A 프로세스가 스케줄링 -> A가 semWait() 호출 -> s 소비 -> s = 0 -> A 실행
B 프로세스 semWait() 호출 -> s <= 0 이므로 s = -1한 후, B 블록 큐 이동
A 프로세스 타임아웃으로 준비 큐 대기
D 프로세스 semSignal() 호출로 s++, 이어서 블록 큐에서 프로세스 B 호출
B가 실행 후, 종료
C가 준비 큐에서 스케줄링 -> semWait()를 호출 -> s = 0이므로 s--, C는 블록
A가 준비 큐에서 스케줄링 -> semWait()를 호출 -> s = -1이므로 s--. A는 블록
D가 준비 큐에서 스케줄링 -> semSignal()를 호출 -> s++, s-= -1, 블록된 'C' 실행
약성 세마포어
약성 세마포어는 큐를 사용하거나 혹은 다른 매커니즘을 사용할 수 있습니다. 만약 적용되는 프로세스가 실행 순서에 대한 요구사항이 없다면 다른 동기화 매커니즘을 사용하여 실행 순서를 관리할 수 있습니다. 따라서, 약성 세마포어는 '기아' 상태가 발생할 수 있습니다.
6. 상호 배제
세마포어를 사용할 경우, 공유 자원에 접근하려는 n개의 프로세스를 상호 배제할 수 있습니다.
프로세스가 공유 자원을 접근하려는 코드 부분이 임계영역으로 정의되고, 긱 프로세스는 임계영역에 들어가기 전 semWait를 호출합니다. s의 값의 범위에 따라 해당 프로세스의 블록이 결정됩니다.
만약 s가 양수라면 임계영역 내부로 입장하고, 임계 영역에서 나오며 s를 다시 증가킵니다.
따라서, s.count는 다음과 같이 정리할 수 있습니다.
s.count >= 0 : s.count는 현재 임계영역에 블록됨이 없이 진입할 수 있는 프로세스의 수를 나타냅니다.
s.count < 0: s.count의 절대값은 s.queue에 블록되어 있는 프로세스의 수를 나타냅니다.
import java.util.*;
class Solution {
List<Integer> heights = new ArrayList<>();
public double[] solution(int k, int[][] ranges) {
double[] answer = new double[ranges.length]; // 정답 배열
heights.add(k); // k를 단계별로 처리한 값을 heights에 넣기 위한 arrayList
while (k > 1) {
if (k % 2 == 0) k /= 2;
else {
k *= 3;
k++;
}
heights.add(k);
}
double[] dp = new double[heights.size()]; // dp 선언
// 너비 단위는 1 (ranges가 int 이차원 배열이므로), 인덱스 i의 k 와 i - 1의 k로 사다리꼴 넓이 구하기
for (int i = 1; i < heights.size(); i++) {
dp[i] = dp[i - 1] + (heights.get(i - 1) + heights.get(i)) * 1.0 / 2; // 이전 dp를 더함으로써 누적합
}
int last = heights.size() - 1;
for (int i = 0; i < ranges.length; i++) {
int a = ranges[i][0]; // 범위 a
int b = ranges[i][1]; // 범위 b
if (a > heights.size() || (last + b) < a) { // 정적분되는 실제 범위가 유효하지 않은 경우
// ex) last : 6, last = -3, a = 4 ==> 양수 정적분 불가
answer[i] = -1.0;
continue;
}
double total = dp[last];
answer[i] = total - dp[a] - (dp[last] - dp[last + b]); // 전체에서 양측 범위에 해당하는 적분 결과 빼서 중간 범위 구하기
}
return answer;
}
}
2. 주의할 점
문제에서, 1-1, 1-2로 되어 있는 파트 단계별 순서가 아닌 분기되는 조건이므로 2로 나누었을 때, 홀수가 되더라도 1-1 이후, 1-2로 가는 것이 아니라 2번 스텝으로 가야 합니다.
적분 구간이 다소 헷갈릴 수 있었습니다. range = [0, 0]이 전구간 적분 결과가 나오는 이유는, a에서 b까지 적분 되는 결과에서 range[0]이 의미하는 바는 x = 0에서 range[0]만큼 떨어진 구간이고, range[1]은 x = lastIndex 에서 range[1]만큼 더한 (range[1]이 음수이므로) 범위를 의미합니다. 따라서, [0, 0]은 x = 0 - 0 = 0, x = last - 0 = last이므로 전 구간 적분입니다.
a 에서 b까지 이루어지는 적분에서 만약 a 가 b 보다 큰 경우는 -1.0을 리턴하도록 문제에서 정의되어 있으므로, 이 부분을 반드시 체크해야합니다.!
정말 한 없이 실력이 모자다라는 것을 느끼고 십 분간 좌절한 후, 현실을 냉철하게 분석하는 시간이 되었습니다.
먼저, 간단하게 회고를 남기고 이어서 프로그래머스 미로 탈출 문제를 해결한 과정을 정리하도록 하겠습니다.
1. 회고
제가 본시험은 120분간 4문제를 해결해야 했습니다. 최초 목표는 60, 60분씩 두 문제를 해결하고자 하는 마음으로 출발했습니다.
하지만 1번 문제의 다소 복잡한 구현에서 105분을 소비해 버렸습니다. 예상하지 못한 테스트 케이스를 제가 임의로 추가한 후에, 처음 작성한 문제가 무엇이었는지 파악하고 수정하는데 많은 시간을 소모했습니다. 결국 1번에서 제공해 주신 테스트 케이스는 성공했지만, 2번 문제를 분석할 시간도 없이 2번을 흐적이다가 끝났습니다.
끝난 후, 문제의 난이도와 별개로 정말 제 실력이 많이 부족하다는 것을 느끼게 되었습니다. 하지만 큰 경험으로 현재 문제점을 파악하고 앞으로의 공부 방향을 어떻게 잡아야 하는지 느끼게 되었습니다. 알고리즘뿐만 아니라, 특정 문제가 주어졌을 때, 이를 구현하는 실력과 빠른 시간 내에 문제를 파악하고 코드를 작성해야하는 것을 느끼게 되었습니다.
이에 현실을 자각할 수 있었고, 헤이해진 몸과 정신을 다 잡을 수 있는 기회가 되었습니다. 좌절할 시간도 아깝기에 바로 다른 부분을 공부하며 흐름이 끊기지 않도록 하였습니다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
import java.util.ArrayDeque;
import java.util.Queue;
import static java.lang.Integer.parseInt;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String[] inputs = br.readLine().split(" ");
int n = parseInt(inputs[0]);
int m = parseInt(inputs[1]);
WallMap wallMap = new WallMap(n, m);
for (int i = 0; i < n; i++) {
String str = br.readLine();
for (int j = 0; j < m; j++) {
wallMap.addMap(i, j, str.charAt(j));
}
}
System.out.println(wallMap.findShortRoad());
}
}
class WallMap {
static final int[] D_X = {1, 0, -1, 0};
static final int[] D_Y = {0, 1, 0, -1};
char[][] map; // 입력한 벽을 저장할 2차원 배열
boolean[][][] visited; // 방문 여부 3차원 배열
class Road {
int x; // x 좌표
int y; // y 좌표
int step; // bfs 단계
boolean destroyed; // 길에 벽이 있다면 파괴 여부
Road(int x, int y, int step, boolean destroyed) {
this.x = x;
this.y = y;
this.step = step;
this.destroyed = destroyed;
}
}
WallMap(int n, int m) {
map = new char[n][m];
visited = new boolean[n][m][2];
}
void addMap(int x, int y, char c) {
map[x][y] = c;
}
int findShortRoad() {
Queue<Road> queue = new ArrayDeque<>(); // 큐 생성
queue.add(new Road(0, 0, 1, false)); // 첫 번째 길 등록 (x = 0, y = 0, step = 1, 파괴 X)
// bfs
while(!queue.isEmpty()) {
Road road = queue.poll(); // 큐에서 저장한 Road 인스턴스 빼기
if (road.x == map.length - 1 && road.y == map[0].length - 1) {
return road.step; // 만약 찾아야 하는 마지막 배열에 위치한 경우 종료
}
for (int k = 0; k < D_X.length; k++) {
int newX = road.x + D_X[k]; // dx dy
int newY = road.y + D_Y[k];
if (validRange(newX, newY)) continue; // 인덱스 유효한 배열 확인
if (map[newX][newY] == '0') { // 만약 map에 있는 값이 벽이 아니라면
if (!road.destroyed && !visited[newX][newY][0]) {
// 큐에 new Road()로 새로운 길의 x, y, step + 1, 벽 파괴 X 입력하기
queue.add(new Road(newX, newY, road.step + 1, false));
visited[newX][newY][0] = true; // 방문 여부 등록
}
// 만약 길이 파괴된 상태, 방문하지 않은 경우 true를 queue에 넣기
else if (road.destroyed && !visited[newX][newY][1]) {
queue.add(new Road(newX, newY, road.step + 1, true));
visited[newX][newY][1] = true;
}
}
// 만약 새로운 길이 벽이라면, 파괴되지 않은 경우만 큐에 넣기
else if (map[newX][newY] == '1') {
if (!road.destroyed) {
queue.add(new Road(newX, newY, road.step + 1, true));
visited[newX][newY][1] = true;
}
}
}
}
return -1;
}
boolean validRange(int x, int y) {
return x < 0 || y < 0 || x >= map.length || y >= map[0].length;
}
}
2. 풀이 중 어려웠던 점
이전 BFS 문제를 해결할 때는 인스턴스 배열을 생성해서 그 안에 인스턴스를 넣고 초기화하는 작업을 수행했습니다. 만약 입력 시점에 1이 입력된다면 possibleBreakWall 리스트에 추가하는 방법을 했습니다.
하지만, 시간초과가 발생했고 비효율적인 방법이었다는 점을 확인했습니다. 만약, Road 배열을 선언하고 그 안에 road 인스턴스를 넣는다면 벽을 깬 방법이 올바르지 않을 때, 매번 배열에 등록된 인스턴스를 전부 초기화하는 작업을 수행했어야 했습니다.
class WallMap {
Road[][] roads;
List<Road> possibleBreakWall = new ArrayList<>();
이 문제를 해결하기 위해,
따라서, char[][] map이라는 배열을 등록하여, Queue에 넣을 때마다 인스턴스에 상태를 기록하는 방법을 적용했습니다.
이 방법의 장점은
BFS는 계속 순회하되, map이라는 벽을 기록한 상태 정보는 바뀌지 않기 때문에 Queue에 등록되는 인스턴스의 벽을 깼는지 여부를 파악하고 다음 스텝에 새로운 Road 인스턴스를 생성하며 현재 스텝 + 1, 벽 깬 여부 true만 이어서 등록하면 됩니다.
즉, Queue에 있는 road는 해당 좌표와 현재 벽을 깼는지 그리고 방문한 상태인지만 파악한다면
1 -> 2 -> 3(벽 깸) -> 5 -> 7 (벽 못깸)
-> 4 -> 6 -> 7(벽 깸) -> 도착지
-> 9(벽 깸) -> 4 이미 2번 노드의 자식 노드인 4번 노드에서 먼저 방문 했으므로 종료
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
import java.util.Queue;
import java.util.ArrayDeque;
import java.util.StringTokenizer;
import static java.lang.Integer.parseInt;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int n = getInt(st);
int m = getInt(st);
Maze maze = new Maze(n, m); // 미로 인스턴스 생성
String str;
for (int i = 0; i < n; i++) {
str = br.readLine();
for (int j = 0; j < m; j++) {
maze.setInit(i, j, Character.getNumericValue(str.charAt(j))); // 미로의 1 혹은 0 입력
}
}
maze.findDestination(); // 미로 목적지 찾기 메서드
maze.printStep(); // 정답을 찾기 위한 깊이를 출력
}
static int getInt(StringTokenizer st) {
return parseInt(st.nextToken());
}
}
class Maze {
static int[] D_X = {1, 0, -1, 0}; // 좌표
static int[] D_Y = {0, 1, 0, -1};
Room[][] rooms; // 미로의 방 이차원 배열
class Room {
int x; // x 좌표
int y; // y 좌표
int step; // 큐에 들어 간 깊이
int num; // 1 or 0
boolean visited; // 방문 여부
Room (int x, int y, int num) {
this.x = x;
this.y = y;
this.num = num;
}
}
Maze(int n, int m) {
rooms = new Room[n][m]; // 생성자로 방의 이차원 배열 생성
}
void setInit(int x, int y, int num) {
rooms[x][y] = new Room(x, y, num); // 배열의 좌표와 숫자로 초기화
}
void findDestination() {
Queue<Room> queue = new ArrayDeque<>(); // queue 생성
rooms[0][0].visited = true; // 0, 0 좌표 방문 처리
rooms[0][0].step = 1; // 0, 0 좌표 단계 설정
queue.add(rooms[0][0]); // 큐 추가
bfs(queue); // bfs 호출
}
void bfs(Queue<Room> queue) {
while (!queue.isEmpty()) { // queue가 빌 때 까지 반복
Room room = queue.poll(); // queue에서 room 빼기
if ((room.x == rooms.length - 1) && (room.y == rooms[0].length - 1)) {
break; // 만약 마지막 위치에 도달한다면 반복문 종료
}
for (int k = 0; k < 4; k++) {
int newX = D_X[k] + room.x;
int newY = D_Y[k] + room.y;
if (validRange(newX, newY)) {
rooms[newX][newY].visited = true; // 방문 여부 등록
rooms[newX][newY].step = room.step + 1; // queue에 등록된 부모 노드의 깊이 + 1
queue.add(rooms[newX][newY]); // 큐 등록
}
}
}
}
void printStep() {
System.out.println(rooms[rooms.length - 1][rooms[0].length - 1].step);
}
boolean validRange(int x, int y) {
return x >= 0 && y >= 0 && x < rooms.length && y < rooms[0].length &&
!rooms[x][y].visited && rooms[x][y].num == 1;
}
}
<Boj1697>
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
import java.util.StringTokenizer;
import java.util.Queue;
import java.util.ArrayDeque;
import static java.lang.Integer.parseInt;
public class Boj1697 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int n = parseInt(st.nextToken());
int k = parseInt(st.nextToken());
HideAndSeek hideAndSeek = new HideAndSeek(n, k);
hideAndSeek.findTime();
hideAndSeek.printTime();
}
}
class HideAndSeek {
static final int MAX_DISTANCE = 100001; // 최대 거리 (0, 10만 일 경우)
Location[] locations = new Location[MAX_DISTANCE];
int n; // 수빈 위치
int k; // 동생 위치
class Location {
int x; // 위치 좌표
int t; // 걸린 시간
boolean visited; // 방문 여부
Location(int x) {
this.x = x;
}
}
HideAndSeek(int n, int k) { // 생성자로 Location[] 배열에 location 등록
this.n = n;
this.k = k;
for (int i = 0; i < MAX_DISTANCE; i++) locations[i] = new Location(i);
}
void findTime() {
Queue<Location> queue = new ArrayDeque<>();
locations[n].visited = true;
queue.add(locations[n]); // 먼저 수빈 위치의 인스턴스를 큐에 등록
bfs(queue); // bfs 시작
}
void bfs(Queue<Location> queue) {
int d;
while(!queue.isEmpty()) {
Location location = queue.poll(); // 큐에 있는 location 인스턴스 추출
if (location.x == k) break; // 만약 시간이 같다면 break;
d = location.x;
int[] dx = {d + 1, d - 1, d * 2};
// 만약 현재 위치에서 dx만큼 변한 것이 0보다 크고, 최대 거리를 넘지 않고, 방문 X라면
for (int z : dx) {
if (z >= 0 && z < MAX_DISTANCE && !locations[z].visited) {
locations[z].visited = true;
locations[z].t = location.t + 1; // 다음에 탐색할 location의 시간을 1 추가
queue.add(locations[z]);
}
}
}
}
void printTime() {
System.out.println(locations[k].t);
}
}
1697번은 수빈과 동생의 위치를 x로 놓은 후, 우리가 찾아야 하는 t를 step으로 설정합니다!
2. Queue로 BFS를 구현할 때, step 처리 반드시 설정하기!
void bfs(Queue<Room> queue) {
while (!queue.isEmpty()) {
Room room = queue.poll();
if ((room.x == rooms.length - 1) && (room.y == rooms[0].length - 1)) {
break;
}
for (int k = 0; k < 4; k++) {
int newX = D_X[k] + room.x;
int newY = D_Y[k] + room.y;
if (validRange(newX, newY)) {
rooms[newX][newY].visited = true;
rooms[newX][newY].step = room.step + 1;
queue.add(rooms[newX][newY]);
}
}
}
}
이 문제는 얼마나 최단 거리로 도착할 수 있는가를 찾는 문제이므로 노드를 삽입한 부모 노드의 깊이에 1을 더하는 것이 중요합니다.
BFS는
1 -> 2 -> 3 순서로 Queue에 넣고 poll하면, 1번 노드가 출력이 되고 1번 노드에 인접한 4, 5 번을 queue에 넣고,
2번 노드를 빼서 인접한 노드 6, 7을 넣게 되면 남은 노드의 처리 순서는 3 -> 4 -> 5 -> 6 -> 7 입니다.
이때, 중요한 점이, 4 5 6 7 의 부모 노드가 무엇인지 모를 수 있으므로 깊이 처리가 어려울 수 있습니다.
따라서, 큐에 등록할 때, 부모 노드 깊이 + 1를 설정해야 큐에서 노드를 뺐을 때, 해당 노드의 깊이를 파악할 수 있습니다.!
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
import java.util.Collections;
import java.util.List;
import java.util.ArrayList;
public class Boj2667 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
Villa villa = new Villa(n);
for (int i = 0; i < n; i++) {
String str = br.readLine();
villa.init(i, str); // villa 초기화
}
List<Integer> villas = villa.calculateTotalVilla();
Collections.sort(villas); // villa 정렬
System.out.println(villas.size()); // 다른 단지 수 출력
StringBuilder sb = new StringBuilder();
for (Integer v : villas) {
sb.append(v).append('\n');
}
System.out.println(sb); // 단지의 하우스 출력
}
}
class Villa {
class House {
int num; // 하우스 1 or 0
boolean visited; // 방문 여부
house(int num) {
this.num = num;
}
}
static int count; // static으로 단지 개수 출력
static final int[] D_X = {-1, 0, 1, 0}; // 왼 - 오 좌표
static final int[] D_Y = {0, 1, 0, -1}; // 상 - 아 좌표
House[][] houses; // 하우스 이차원 배열
List<Integer> counts = new ArrayList<>(); // count를 담을 list
Villa(int n) {
houses = new House[n][n];
} // 생성자
void init(int idx, String str) {
for (int i = 0; i < houses.length; i++) {
houses[idx][i] = new house(Character.getNumericValue(str.charAt(i))); // 초기화
}
}
List<Integer> calculateTotalVilla() { // 총 빌라 수 구하기
for (int i = 0; i < houses.length; i++) {
for (int j = 0; j < houses[0].length; j++) {
// 한번도 방문하지 않으면서 num이 1인 하우스 dfs
if (!houses[i][j].visited && houses[i][j].num == 1) {
count = 0;
dfs(i, j);
counts.add(count);
}
}
}
return counts;
}
private void dfs(int x, int y) {
if ((!houses[x][y].visited) && (houses[x][y].num == 1)) {
houses[x][y].visited = true; // 방문한 곳 true 처리
++count;
for (int k = 0; k < 4; k++) {
int newX = D_X[k] + x; // 앞 서 정의한 x 좌표
int newY = D_Y[k] + y; // 앞 서 정의한 y 좌표
if (validRange(newX, newY)) dfs(newX, newY); // dfs 재귀
}
}
}
// house의 배열에 유효한 인덱스인지 판단
private boolean validRange(int x, int y) {
return (x >= 0) && (y >= 0) && (x < houses.length) && (y < houses.length);
}
}
<Boj1012>
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
import java.util.List;
import java.util.ArrayList;
import java.util.StringTokenizer;
import static java.lang.Integer.parseInt;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st;
int t = parseInt(br.readLine());
int[] result = new int[t];
int m, n, k;
for (int i = 0; i < t; i++) {
st = new StringTokenizer(br.readLine());
m = getInt(st);
n = getInt(st);
k = getInt(st);
Field field = new Field(m, n);
for (int j = 0; j < k; j++) {
st = new StringTokenizer(br.readLine());
field.cabbages[getInt(st)][getInt(st)] = field.setCabbage();
}
field.calculateWhiteBug(m, n);
result[i] = field.counts.size();
}
for (int r : result) {
System.out.println(r);
}
}
static int getInt(StringTokenizer st) {
return parseInt(st.nextToken());
}
}
class Field {
static final int[] D_X = {1, 0, -1, 0};
static final int[] D_Y = {0, 1, 0, -1};
Cabbage[][] cabbages;
List<Integer> counts = new ArrayList<>();
class Cabbage {
int num;
boolean visited;
Cabbage(int num) {
this.num = num;
}
}
Field(int m, int n) {
cabbages = new Cabbage[m][n];
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
cabbages[i][j] = new Cabbage(0);
}
}
}
Cabbage setCabbage() {
return new Cabbage(1);
}
void calculateWhiteBug(int m, int n) {
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (validRange(i, j) && !cabbages[i][j].visited && cabbages[i][j].num == 1) {
dfs(i, j);
counts.add(1);
}
}
}
}
void dfs(int x, int y) {
if (!cabbages[x][y].visited && cabbages[x][y].num == 1) {
cabbages[x][y].visited = true;
for (int i = 0; i < 4; i++) {
int newX = D_X[i] + x;
int newY = D_Y[i] + y;
if (validRange(newX, newY)) dfs(newX, newY);
}
}
}
boolean validRange(int x, int y) {
return x >= 0 && y >= 0 && x < cabbages.length && y < cabbages[0].length;
}
}
2. 중요한 포인트
- dfs를 적용하기 위해, 방문 가능한 하우스(노드)가 무엇인지 판단하기 위해 visited라는 boolean을 설정해야 합니다.
- ArrayIndexOutOfBoundsException이 발생할 수 있으므로 새롭게 생성되는 newX, newY가 x >= 0, y >= 0 그리고 house.length의 길이보다 작아야 houses[][] 배열에 인덱스로 접근할 수 있습니다.
3. 재귀적 원리로 dfs() 활용하기
void dfs(int idx) {
Node root = nodes[idx]; // root node 가져오기
root.visitedDfs = true; // 방문 처리
listDfs.add(root.u); // 방문한 것 출력을 위해 배열에 추가
for (Node n : root.adjacent) {
if (!n.visitedDfs) {
n.visitedDfs = true;
dfs(n.u);
}
}
}
일반적으로 dfs를 구현하는데 사용되는 샘플 코드는 다음과 같습니다.
nodes[idx]에서 root 노드를 가져온 후, node에 인접한 adjacent 노드들을 가져온 후, 방문 여부를 판단하고 방문하지 않았다면 방문 여부를 등록한 후 dfs()로 메서드를 다시 호출합니다.
이와같은 원리로 이 문제에서도 방문 여부 false를 판단하고 문제에서 추가로 제시한 1인 번호인지를 체크하고 방문 여부를 true로 설정합니다. 이 후 인접한 노드 (여기서는 인접 좌표)를 설정한 후 인접한 노드로 다시 dfs를 적용합니다.
private void dfs(int x, int y) {
if ((!houses[x][y].visited) && (houses[x][y].num == 1)) {
houses[x][y].visited = true; // 방문한 곳 true 처리
++count;
for (int k = 0; k < 4; k++) {
int newX = D_X[k] + x; // 앞 서 정의한 x 좌표
int newY = D_Y[k] + y; // 앞 서 정의한 y 좌표
if (validRange(newX, newY)) dfs(newX, newY); // dfs 재귀
}
}
}
이번 포스팅은 의존성 주입과 profile 설정으로 filter의 설정 정보를 다르게 적용하는 과정을 정리하도록 하겠습니다.
1. 문제 상황
MSA 아키텍처에서 Gateway와 Member 서버는 서로 같은 Redis 서버 (Aws ElasticCache)를 사용하고 있습니다. 다른 서버는 Gateway로부터 라우팅을 수행하지만, 공통의 Redis를 사용하지 않기 때문에 컨트롤러 혹은 핸들러 API 테스트를 진행하는 과정에서 Gateway에서 헤더 정보 인증이 안될 수 있습니다.
gateway-server는 redis 6379 port에 연결되어 있습니다. gateway는 AuthorizationHeaderFilter에서 다음과 같이 request를 파싱 하여 jwt의 유효성 검사를 진행하고, 실제 6379 redis 서버에 jwt가 존재하고, 로그인 세션이 등록된 유저인지 판단합니다.
하지만, 문제가 되는 다른 서버들은 gateway와 다른 6380 port의 다른 redis 서버를 사용하고 있으므로, 토큰을 공유할 수 없습니다. 즉, 비즈니스 테스트 과정에서 임의의 jwt 토큰을 발급하여 헤더 정보로 보내더라도 gateway에서는 유효성을 검사한 후 실제 redis 서버에 존재하는지 파악하기 때문에, 인증 에러가 발생하여 비즈니스 로직 테스트를 할 수 없습니다.
매번 gateway에 토큰을 추가하기 위해 member 서버를 기동하여 토큰을 추가하는 방법이나, 혹은 Gateway에서 역으로 member에 대한 토큰을 발급하는 방법이 있는데 이 방법 모두 비효율적이며, 테스트를 위해 다른 부가로직을 추가하는 것은 좋지 못한 방법이라고 생각하였습니다.
따라서, 로컬 환경에서 테스트를 위해 Gateway를 기동할 때는 jwt의 유효성만 검사하고, 통과시키는 filter를 적용할 필요성이 있었습니다.
2. 문제 파악하기
@Slf4j
@Component
@RequiredArgsConstructor
public class AuthorizationHeaderFilter extends AbstractGatewayFilterFactory<AuthorizationHeaderFilter.Config> {
--- 중략 ---
public static class Config {}
@Override
public GatewayFilter apply(Config config) {
return (exchange, chain) -> {
ServerHttpRequest request = exchange.getRequest();
if (isWhiteList(request.getURI().getPath())) return chain.filter(exchange);
validateAuthorizationHeaders(request);
try {
if (validateRequestHeader(request)) return chain.filter(exchange);
} catch (JsonProcessingException e) {
return onError(exchange, ExceptionMessage.BADREQUEST, HttpStatus.BAD_REQUEST);
}
return onError(exchange, ExceptionMessage.BADREQUEST, HttpStatus.BAD_REQUEST);
};
}
}
현재 AuthorizationHeaderFilter는 여러 가지 검증 처리와, 토큰 유효성 검사 및 실제 토큰와 로그인 세션이 Redis에 저장되어 있는지 판단합니다. 따라서, 이 네 가지 조건에 하나라도 위배된다면 인증될 수 없습니다.
AuthorizationHeaderFilter는 AbstractGatewayFilterFactory의 추상클래스를 확장한 클래스로 apply를 Override 하면 GatewayFilter를 생성하고 있습니다.
AbstractGatewayFilterFactory는 Spring Cloud Gateway에서 사용되는 필터를 생성하는 추상 클래스입니다. GatewayFilter는 Spring Cloud에서 사용하는 필터로 헤더 정보를 처리하거나 요청 및 응답을 변경하는 역할을 수행합니다.
AbstractGatewayFilterFactory는 Config 설정 정보에 따라 GatewayFilter에 대한 설정 정보를 다르게 할 수 있습니다.
여기서 Config는 특정 인터페이스가 정해져 있지 않는 제네릭 타입이므로, 사용자가 Custom하게 수정할 수 있다는 장점이 있었습니다. 따라서 저는 Config 클래스를 Custom하게 변경하여 profile에 따라 다르게 적용되도록 구현하였습니다.
3. 자바의 다형성과 의존관계 주입하기
자바의 최고 장점은 다형성인 것 같습니다. 특정 인터페이스를 구현하는 다양한 구현체가 있을 때 인터페이스로 캐스팅 할 수 있습니다. 스프링의 의존관계 주입과 함께 사용하면, 특정 상황에 따라 다른 구현체가 필요할 때 인터페이스로 의존 관계를 주입 받은 후 스프링 서버의 기동시에 구현체 빈 등록을 스프링에게 위임할 수 있습니다.
따라서, AuthorizationConfig라는 인터페이스를 선언한 후 공통 클래스를 추상 클래스로 선언한 후, AuthorizationDefaultConfig와 AuthorizationDevConfig로 AbstractAuthorizationConfig 클래스를 상속한다면, AuthorizationConfig로 의존관계를 주입 받을 수 있습니다. 스프링은 AuthoziationConfig에 대한 구현체가 하나라면 바로 스프링 빈으로 등록하여 구현체가 적용되도록 해줍니다.
장점은 이렇게 서로 다른 구현체를 모두 스프링 빈을 등록하면, 스프링은 어떤 구현체를 선택해야할 지 선택할 수 없기 때문에 서버 기동시에 개발자에게 에러를 발생시킵니다. (정말 엄청난 기술입니다 ㅠㅠ) 이러한 에러를 바탕으로 복수의 구현체가 등록된 것을 확인하고 에러를 바로 잡을 수 있습니다.
그렇다면 이제 복수의 구현체가 등록되는 문제를 해결하기 위해 Profile을 설정하는 과정을 코드로 함께 정리하도록 하겠습니다.
4. 코드 수정하기
먼저 AuthorizationConfig 인터페이스를 선언합니다.
이 인터페이스의 역할은 AuthorizationHeader를 검증하고, 토큰 유효성 및 존재 여부를 판별합니다.