안녕하세요. 회사와 함께 성장하고 싶은 KOSE입니다.
우리가 흔히 사용하는 카카오톡과 같은 채팅 어플은, 실시간 처리가 매우 중요합니다.
친구가 메세지를 보냈는데 새로고침 하기 전까지 메세지가 전송되지 않는다면 해당 어플은 사용하지 않을 것입니다.
이를 방지하기 위해 사용하는 개념이 '소켓'입니다.
이번 포스팅은 MSA 아키텍처의 Liar-Game의 실시간 대기실 역할을 수행한 wait-server 프로젝트를 정리하며 웹소켓 연결 과정과 예외처리에 대해서 자세하게 정리하도록 하겠습니다. 제 스프링 부트 버전은 3.0.2로 최신 버전입니다.
(따라서, 최신 3.x.x에 호환되는 기능으로, 아직 레퍼런스가 많이 부족하여 오픈 소스로 참고하시면 좋습니다!!!!)
1. Socket과 SpringWebSocket
소켓은 컴퓨터 네트워크를 통해 다른 컴퓨터나 프로세스와 통신하기 위한 엔드포인트로 서로 다른 시스템 간에 데이터를 교환할 수 있도록 돕는 전송 계층의 프로토콜입니다.
소켓은 TCP 소켓과 UDP 소켓으로 구분할 수 있습니다. TCP 소켓은 연결형 통신으로 신뢰성 있는 데이터 전송을 보장하여 전송 순서와 오류 수정을 처리할 수 있습니다 대표적으로 웹 서버와 브라우저 간의 통신이 있습니다.
UDP 소켓은 데이터의 신뢰성을 보장하지 않지만 낮은 지연 시간을 갖기 때문에 실시간 게임과 같은 스트리밍 서비스에 적합합니다.
스프링의 Websocket 모듈은 웹 소켓 프로토콜을 지원하며 서버와 클라이언트 사이의 양방향 통신을 제공하여 빠른 데이터 전달을 가능하도록 합니다.
Spring WeboSocket은 WebSocket 서버 및 클라이언트를 개발하는 데 필요한 다양한 기능을 제공하며, 세션관리, 메시지 매핑으로 클라이언트에게 수신된 메시지를 빠르게 처리할 수 있습니다.
(저는 HTTP/1.1에서 사용하는 WebSocket을 적용하였지만 추후 모든 개발이 완성작업에 들어갈 때, SSL/TLS을 적용하여 HTTP/2를 도입할 예정입니다. 이 글 다음 편으로는 HTTP/1.1과 HTTP/2 사이의 Websocket 성능을 분석하도록 하겠습니다.)
2. Wait-Server 비즈니스 로직 및 WebSocket 적용 부분 정리하기
Wait-Server의 역할은 클라이언트가 Liar-Game을 수행하기 전에 게임 대기실 역할을 수행하는 장소입니다. 제가 중학생 때 좋아했던 스타크래프트나 혹은 카트라이더 등은 게임 대기실을 제공하는 서버로 많은 트래픽을 유발할 수 있는 곳입니다. 실시간으로 입장이 가능해야 하고, 클라이언트가 방을 개설하면 방의 리스트가 제공되어야 하며, 같은 대기실에 있는 사람들과 다른 대기실에 존재하는 인원들은 격리된 공간을 제공해야 합니다.
뿐만 아니라, 게임 대기실은 인원 제한도 제공해야 합니다. 보통 게임을 생각하면 4명 혹은 5명 인원 제한을 둘 수 있습니다.
따라서, 소켓으로 특정 대기실에 접속한 인원을 저장하고 인원 대기실의 만원 처리등을 수행해야 하며, 게임 대기실 호스트가 만약 방을 나가게 되면 방 전체를 없애는 핵심 기능도 수행해야 합니다.
따라서, Wait-Server의 핵심 비즈니스 로직을 다음과 같이 정리할 수 있습니다.
- 개별적인 게임 대기실은 격리된 공간에서 제공되어야 합니다. 다른 대기실은 서로 데이터를 공유할 수 없습니다.
- 유저(호스트 포함)는 동일 시간에 단 하나의 게임 대기실에만 입장할 수 있습니다. 만약 다른 대기실에 입장 요청을 하면 기존에 있던 게임 대기실에서 자동 퇴장 조치되어야 합니다.
- 게임 대기실은 인원 제한이 있으며 클라이언트가 입장 및 퇴장을 할 때, 빠른 입출력으로 대기실 현황을 업데이트해야 합니다.
- 만약 호스트가 대기실 퇴장을 요청하면 현재 대기실에 존재하는 모든 유저는 대기실에서 퇴장 조치 됩니다.
- 호스트가 게임 가능 최저 인원을 달성하면 게임을 시작할 수 있으며, wait-server에서 game-server로 요청이 위임되어야 합니다.
여기서 Controller는 게임 대기실의 리스트를 보여주는 역할을 수행하고 WebSocketHandler는 게임 대기실 내부의 현황을 처리하는 데 사용하였습니다.
두 기능을 분리한 이유는 게임 대기실 리스트를 보여주는 역할은 상대적으로 실시간성이 보장되지 않아도 된다고 판단하였습니다.
만약 게임 입장하려고 했는데, 만원이 된 경우 요청이 거절되고 다시 리스트업이 될 수 있습니다. 하지만, 게임 대기실의 경우 입장한 A 클라이언트는 다른 유저가 이 방에 접속했는지 실시간으로 확인할 수 있어야 합니다. 따라서, 원활한 게임 대기실의 역할을 수행하기 위해 양방향성을 제공하는 WebSocket을 활용하고, 비교적 리스트업의 역할을 수행해야 하는 게임 대기실 목록은 Controller로 적용하였습니다. 정리하면, Wait-Server는 게임 대기실 목록은 Controller, 대기실에 입장하는 순간부터는 외부와 격리된 대기실을 제공해야 하므로 WebSocket으로 비즈니스 로직을 구현하였습니다.
3. WebSocket으로 대기실 구현하기 (Controller / Handler)
WebSocket을 사용하려면 의존성 주입을 받아야 합니다.
implementation 'org.springframework.boot:spring-boot-starter-websocket'
이후, Configuration을 추가하여 Websocket의 messageBroker를 설정합니다.
@Configuration
@RequiredArgsConstructor
@EnableWebSocketMessageBroker
public class WebSocketConfig implements WebSocketMessageBrokerConfigurer {
private final WebsocketSecurityInterceptor websocketSecurityInterceptor;
@Override
public void registerStompEndpoints(StompEndpointRegistry registry) {
registry.addEndpoint("/wait-service/wait-websocket")
.addInterceptors(new CustomHandshakeInterceptor())
.setAllowedOriginPatterns("*")
.withSockJS();
}
@Override
public void configureMessageBroker(MessageBrokerRegistry registry) {
registry.enableSimpleBroker("/wait-service/waitroom/sub", "/queue");
registry.setApplicationDestinationPrefixes("/wait-service");
}
@Override
public void configureClientInboundChannel(ChannelRegistration registration) {
registration.interceptors(websocketSecurityInterceptor);
}
}WebSocketMessageBrokerConfigurer는 WebSocket에서 사용할 MessageBroker를 설정하는 인터페이스입니다.
위임 메서드는 다음과 같습니다.
- configureMessageBroker : 메시지 브로커 옵션 설정하는 메서드로 메세지 핸들러의 라우팅 설정 및 브로커가 사용할 목적지 접두사를 정의합니다.
- registerStompEndpoints: 클라이언트가 WebSocket 서버에 연결하기 위한 엔드포인트입니다.
- confgirueWebSocketTransport: WebSocket 전송에 대한 구성을 제공합니다.
- configureClientInboudChannetl: 클라이언트로부터 수신한 메시지를 처리하는 데 사용되는 채널에 대한 설정입니다.
- configureClientOutBoundChannel: 서버에서 클라이언트로 보내는 메시지를 처리하는데 사용되는 채널을 구성합니다.
그렇다면, setApplicationDestinationPrefixes와 enableSimpleBroker는 무슨 차이일까요?
webSocket의 메세지 브로커는 발행 - 구독 시스템을 따릅니다.
따라서, applicationDestinationPrefixes로 설정되어 있는 접두사로 특정 요청을 보내면,
서버는 내부 핸들로를 통해 서버에서 매칭한 구독 접두사와 연결하여 메시지를 구독하고 있는 클라이언트에게 전달합니다.
저는 Controller와 Mapping Uri를 동일하게 하기 위해 /wait-service를 prefix로 설정하였고, broker는 /wait-service/waitroom/sub으로 설정하였습니다. /queue가 하는 역할은 클라이언트의 요청에 대한 에러를 처리하기 위해 사용하는 브로커로 클라이언트에게 예외 메시지를 전달하기 위해 사용됩니다.

핵심 비즈니스 로직은 waitRoom을 생성하면, 호스트는 waitRoom에 참여하고 다른 유저는 대기실 목록을 클릭하면 waitRoom에 참여 가능한지 파악하고 waitRoom에 입장 허가 하거나 불가 정책을 수행합니다.
(해당 비즈니스 로직은 WebSocket 조금만 정리하도록 하겠습니다.!)
@Getter
@RedisHash("WaitRoom")
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class WaitRoom extends BaseRedisTemplateEntity {
@Id
private String id;
@Indexed
private String roomName;
@Indexed
private String hostId;
@Indexed
private String hostName;
private int limitMembers;
private boolean waiting;
private List<String> members = new CopyOnWriteArrayList<>();
@JsonSerialize(using = LocalDateTimeSerializer.class)
@JsonDeserialize(using = LocalDateTimeDeserializer.class)
private LocalDateTime createdAt;
@JsonSerialize(using = LocalDateTimeSerializer.class)
@JsonDeserialize(using = LocalDateTimeDeserializer.class)
private LocalDateTime modifiedAt;
--- 중략 ---
/**
* 호스트가 방을 만들 경우, WaitRoom에서는 JoinMember(host)를 생성
*/
public JoinMember createJoinMember() {
return new JoinMember(this.getHostId(), this.getId());
}
}
WaitRoom 객체는 대기실의 기타 정보와 참여한 유저를 등록하고, 입장과 퇴장, 입장 가능 여부의 역할이 있습니다.
따라서, WaitRoom에 관련한 참여 유저 추가, 제거, 호스트의 JoinMember 생성 등의 책임을 부여하였습니다.
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@RedisHash("JoinMember")
public class JoinMember {
@Id
private String id;
private String roomId;
public JoinMember(String userId, String roomId) {
this.id = userId;
this.roomId = roomId;
}
--- 중략 ---
}
/**
* waitRoom을 저장
* createWaitRoomDto로 waitRoom의 정보를 얻고, userId로 hostName 불러오기
* waitRoom을 redis에 저장하고, joinMembers를 생성하여 저장한다.
*/
@Override
public String saveWaitRoomByHost(CreateWaitRoomRequest createWaitRoomRequest) {
waitRoomJoinPolicyService.createWaitRoomPolicy(createWaitRoomRequest.getUserId());
MemberNameOnly username = memberService.findUsernameById(createWaitRoomRequest.getUserId());
WaitRoom waitRoom = saveWaitRoomAndStatusJoin(createWaitRoomRequest, username);
return waitRoom.getId();
}
/**
* 호스트가 아닌 다른 유저 대기방 요청 승인
* 게임이 진행 중이거나 현재 게임 중인 유저인 경우, 현재 게임에 참여할 수 없음.
*/
@Override
public boolean addMembers(CommonWaitRoomRequest dto) {
if (!validateNotPlaying(dto.getRoomId(), dto.getUserId())) throw new BadRequestException();
waitRoomJoinPolicyService.joinWaitRoomPolicy(dto.getUserId());
WaitRoom waitRoom = findById(dto.getRoomId());
if (isEnableJoinMembers(dto, waitRoom)) {
return saveWaitRoomAndStatusJoin(dto, waitRoom);
}
throw new BadRequestException();
}
FacadeService에서는 WaitRoom을 생성하면 Redis에 waitRoom을 저장합니다. 이때 유저 추가가 가능하다면 waitRoom에 userId를 추가하고, 더 이상 참여가 불가하면 userId를 저장하지 않습니다.
먼저 waitRoom을 생성하는 구문은 Controller로 작성하였습니다.
@RestController
@RequestMapping("/wait-service")
@RequiredArgsConstructor
public class WaitRoomController {
private final WaitRoomFacadeService waitRoomFacadeService;
@PostMapping("/waitroom/create")
public ResponseEntity createWaitRoom(@Valid @RequestBody CreateWaitRoomRequest dto) {
String waitRoomId = waitRoomFacadeService.saveWaitRoomByHost(dto);
return ResponseEntity.ok().body(SendSuccessBody.of(waitRoomId));
}
클라이언트는 생성된 waitRoomId를 바탕으로 collback으로 uri를 이동한 후 소켓에 연결하여 waitRoom에 join 합니다.
@Slf4j
@Controller
@RequiredArgsConstructor
public class WaitRoomSocketHandler {
private final WaitRoomFacadeService waitRoomFacadeService;
private final SessionManagingWebSocketHandler sessionManagingWebSocketHandler;
/**
* StompHeaderAccessor의 필수 헤더
* {@code @Header} Authorization: 인증 accessToken
* {@code @Header} RefreshToken: 인증 refreshToken
* {@code @Header} UserId: 요청 userId
* {@code @Header} WaitRoomId: 요청 waitRoomId
*/
@MessageMapping("/waitroom/pub/{waitRoomId}/join")
@SendTo("/wait-service/waitroom/sub/{waitRoomId}/join")
public ChatMessageResponse joinMember(@Valid @RequestBody CommonWaitRoomRequest dto,
@DestinationVariable String waitRoomId,
@Header("UserId") String userId,
StompHeaderAccessor stompHeaderAccessor) {
log.info("ChatMessageResponse1 message = {}", dto.getUserId());
if (!userId.equals(dto.getUserId())) throw new WebsocketSecurityException();
waitRoomFacadeService.addMembers(dto);
log.info("ChatMessageResponse2 message = {}", dto.getUserId());
return ChatMessageResponse.of(dto.getUserId(), JOIN);
}
@MessageMapping()은 앞 서 정의한 prefixes를 포함하여 destination으로 매핑하는 역할을 수행합니다.
registry.setApplicationDestinationPrefixes("/wait-service");
@SendTo()는 broker 메시지를 전송하는 역할을 수행합니다. 클라이언트는 enableSimpleBroker로 설정한 destination에 @SendTo에 정의되는 메시지가 매핑된다면 메세지가 전송되게 됩니다.
registry.enableSimpleBroker("/wait-service/waitroom/sub", "/queue");
마찬가지로 조인과, 퇴장, 호스트 방 제거 등을 추가할 수 있습니다.
@MessageMapping("/waitroom/pub/{waitRoomId}/join")
@SendTo("/wait-service/waitroom/sub/{waitRoomId}/join")
public ChatMessageResponse joinMember(@Valid @RequestBody CommonWaitRoomRequest dto,
@DestinationVariable String waitRoomId,
@Header("UserId") String userId,
StompHeaderAccessor stompHeaderAccessor) {
log.info("ChatMessageResponse1 message = {}", dto.getUserId());
if (!userId.equals(dto.getUserId())) throw new WebsocketSecurityException();
waitRoomFacadeService.addMembers(dto);
log.info("ChatMessageResponse2 message = {}", dto.getUserId());
return ChatMessageResponse.of(dto.getUserId(), JOIN);
}
@MessageMapping("/waitroom/pub/{waitRoomId}/delete")
@SendTo("/wait-service/waitroom/sub/{waitRoomId}/delete")
public ChatMessageResponse deleteWaitRoom(@Valid @RequestBody CommonWaitRoomRequest dto,
@DestinationVariable String waitRoomId,
@Header("UserId") String userId,
StompHeaderAccessor stompHeaderAccessor) {
if (!userId.equals(dto.getUserId())) throw new WebsocketSecurityException();
boolean deleteStatus = waitRoomFacadeService.deleteWaitRoomByHost(dto);
return ChatMessageResponse.of(dto.getUserId(), LEAVE, deleteStatus);
}
@MessageMapping("/waitroom/pub/{waitRoomId}/leave")
@SendTo("/wait-service/waitroom/sub/{waitRoomId}/leave")
public ChatMessageResponse leaveMember(@Valid @RequestBody CommonWaitRoomRequest dto,
@DestinationVariable String waitRoomId,
@Header("UserId") String userId,
StompHeaderAccessor stompHeaderAccessor) {
if (!userId.equals(dto.getUserId())) throw new WebsocketSecurityException();
boolean leaveStatus = waitRoomFacadeService.leaveMember(dto);
return ChatMessageResponse.of(dto.getUserId(), LEAVE, leaveStatus);
}
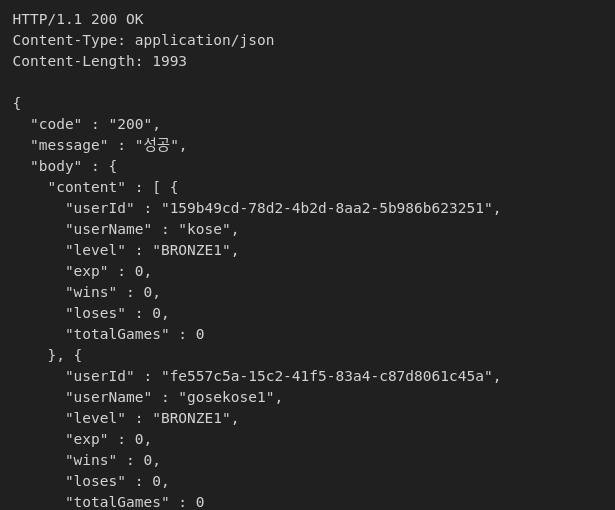
이를 수행하면 다음과 같은 구조도와 예시 모습을 확인할 수 있습니다.
유저는 실시간으로 게임 대기실의 참여 인원을 확인하고 입장하고 퇴장하는 인원을 실시간으로 볼 수 있습니다.

4. Websocket 보안 Interceptor 등록하기
여기서부터 정말 어려워지는 구간이었습니다.! 이 비즈니스 로직에서는 반드시 필요한 stomp 헤더 정보가 없거나, join 한 유저가 아닌 다른 클라이언트가 접근을 시도한다면 대기실 입장을 거부하는 인터셉터 작성이 필요했습니다.
@Slf4j
@RequiredArgsConstructor
@Component
public class WebsocketSecurityInterceptor implements ChannelInterceptor {
private final WaitRoomFacadeService waitRoomFacadeService;
private final AntPathMatcher antPathMatcher;
private final TokenProviderPolicy tokenProviderPolicy;
@Override
public Message<?> preSend(Message<?> message, MessageChannel channel) {
StompHeaderAccessor headerAccessor = StompHeaderAccessor.wrap(message);
if (StompCommand.CONNECT.equals(headerAccessor.getCommand())) {
isValidateWaitRoomIdAndJoinMember(headerAccessor);
}
return message;
}
private void isValidateWaitRoomIdAndJoinMember(StompHeaderAccessor headerAccessor) {
String accessToken = headerAccessor.getFirstNativeHeader("Authorization");
String refreshToken = headerAccessor.getFirstNativeHeader("RefreshToken");
String waitRoomId = headerAccessor.getFirstNativeHeader("WaitRoomId");
String userId = headerAccessor.getFirstNativeHeader("UserId");
if (accessToken == null || refreshToken == null || waitRoomId == null || userId == null)
throw new WebsocketSecurityException();
log.info("validateUserAccessor >>");
validateUserAccessor(validateTokenAccessor(accessToken, refreshToken), userId);
String destination = headerAccessor.getDestination();
log.info("destination = {}", destination);
log.info("destination >>");
if (destination == null) throw new WebsocketSecurityException();
if (isApplyUri(destination)) {
log.info("isJoinedMember >>");
waitRoomFacadeService.isJoinedMember(waitRoomId, userId);
}
}
private String validateTokenAccessor(String accessToken, String refreshToken) {
try {
String userIdFromAccess = tokenProviderPolicy.getUserIdFromToken(tokenProviderPolicy.removeType(accessToken));
String userIdFromRefresh = tokenProviderPolicy.getUserIdFromToken(refreshToken);
if (!userIdFromAccess.equals(userIdFromRefresh)) throw new WebsocketSecurityException();
return userIdFromAccess;
} catch (Exception e) {
throw new WebsocketSecurityException();
}
}
private boolean isApplyUri(String destination) {
return !antPathMatcher.match("/wait-service/waitroom/**/**/join", destination);
}
private void validateUserAccessor(String parseUserId, String headerUserId) {
if (!parseUserId.equals(headerUserId)) throw new WebsocketSecurityException();
}
}
STOMP는 WebSocket과 같은 전송계층 프로토콜 위에서 동작하며 양방향 통신을 쉽게 구현할 수 있도록 하는 Simple Text Orientated Messaging Protocol로 텍스트 기반의 메시징 프로토콜입니다.
StompHeaderAccessor를 활용하면 STOMP 프로토콜에 사용하는 Header 등의 정보를 담아 인증 처리 등을 구현할 수 있습니다.
<여기서 잠깐! Websocket과 Stomp 추가 정리하기>
WebSocket은 데이터를 전송하는 저수준의 프로토콜입니다. 따라서, STOMP와 같은 상위 프로토콜을 함께 사용하여 메시지 전송 및 라우팅 관리에 필요한 고수준의 기능을 수행할 수 있습니다.
STOMP가 WebSocket을 돕는 고수준의 기능은 다음과 같습니다.
- 메시지 교환 패턴 정의: STOMP는 pub-sub와 point-to-point와 같은 메시지 교환 패턴을 정의합니다.
- 메시지 라우팅: STOMP는 메시지 라우팅을 위한 명시적인 목적지를 제공합니다
- 메시지 형식화: STOMP는 메시지를 전송하는데 필요한 명령어, 헤더, 페이로드를 포함합니다.
- 구독관리: STOMP는 클라이언트가 특정 목적에 대해 구독 여부를 설정할 수 있도록 돕습니다.
따라서, Websocket Congiruation에서 설정한 엔드포인트로 MessageMapping기능, 즉 라우팅 기능을 수행할 수 있는 이유도 이처럼 Stomp가 작동하여 WebSocket이 메세지를 발행 구독 할 수 있는 기능을 돕기 때문입니다.
5. WebSocket에서 발생하는 Exception 처리 로직 작성하기
일부 커넥션을 유지해야 하는 예외가 있는 반면, 반드시 커넥션을 종료시켜야 하는 예외가 있습니다. 가령 클라이언트의 실수와 같은 예외는 단순한 예외 메시지 전송으로 처리 가능하지만, 헤더 정보를 임의로 바꾸거나 대기실 접속 가능한 유저가 아닌 클라이언트가 접속하는 경우 커넥션을 제거해야 합니다.
먼저 소스를 정리한 후 이어서 설명을 진행하도록 하겠습니다.!
@Slf4j
@Component
public class CustomWebSocketHandlerDecorator extends WebSocketHandlerDecorator {
private final ConcurrentHashMap<String, WebSocketSession> sessionMap = new ConcurrentHashMap<>();
public CustomWebSocketHandlerDecorator(@Qualifier("customWebSocketHandlerDecorator") WebSocketHandler delegate) {
super(delegate);
}
@Override
public void afterConnectionEstablished(WebSocketSession session) throws Exception {
sessionMap.put(session.getId(), session);
super.afterConnectionEstablished(session);
}
@Override
public void afterConnectionClosed(WebSocketSession session, CloseStatus closeStatus) throws Exception {
sessionMap.remove(session.getId());
super.afterConnectionClosed(session, closeStatus);
}
public void closeSession(String sessionId) throws IOException {
WebSocketSession session = sessionMap.get(sessionId);
if (session != null && session.isOpen()) {
session.close();
}
}
}
WebSocketHandlerDecorator는 Websocket 핸들러 중 하나로 커넥션을 열고 닫고 하는 과정에서 데코레이터 패턴을 구현하며 추가적인 동작을 수행할 수 있도록 돕습니다.
CustomWebSocketHanlderDecorator는 WebSocketHandlerDecorator을 상속하는 클래스로 커넥션을 sessionMap에 등록하고, 커넥션을 강제로 종료하기 위해 closeSession을 호출하여 session.close()를 처리하는 로직을 구현하였습니다.
그런데, CustomWebSocketHanlderDecorator에서 WebSocketSession을 제거하는 것이 어떠한 의미를 가지고 있을까요?
6. WebSocketSession 처리과정 확인하기
기본적으로 Websocket은 hanShakeHandler로 DefaultHandShakeHandler를 기본값으로 설정하고 있습니다.
.setHandshakeHandler(new DefaultHandshakeHandler(new TomcatRequestUpgradeStrategy()))
DefaultHandShakeHandler는 추상 클래스인 AbstractHandShakeHandler를 상속하고 있으며 해당 클래스에서
WebsocketHandler를 파라미터로 받고 있습니다.

스프링은 WebSocketHandler의 구현체로 stomp를 포함한 여러 프로토콜을 처리하는 역할을 수행하는 SubProtocolWebSocketHandler를 제공하고 있습니다.
여기서 WebSocketSession이 등록되고 삭제되는 로직이 수행되고 있습니다.

이는 곧 SubProtocolWebSocketHandler가 WebSession을 파라미터로 받고 있기 때문에, decorator로 감싸서 부가 기능을 수행한다면 exception이 발생했을 때 특정 session을 강제 종료 시킬 수 있음을 의미하였습니다.

여기서 확인할 수 있는 것은 WebsocketSession은 추상 클래스를 포함하더라도 18개가 구현되어 있습니다.
자바의 다형성을 활용하면, WebsocketSession을 구현하고 있는 다양한 구현체를 WebSocketSession으로 캐스팅할 수 있습니다. 따라서, 인터페이스를 타입으로 캐스팅하여 호출한 후 해당 인스턴스를 제거하면, 그 주소값이 의미를 잃게 되므로,
다른 곳에서도 특정 WebSocketSession을 사용할 수 없게 되는 것입니다.
(정말 자바 스프링은 최고입니다....!)
이전에 등록한 WebsocketConfig에 제가 정의한 CustomWebsocketHandlerDecorator를 빈으로 등록한 후 decorator로 추가하겠습니다.
@Override
public void configureWebSocketTransport(WebSocketTransportRegistration registry) {
registry.addDecoratorFactory(this::customWebSocketHandlerDecorator);
}
@Bean
public WebSocketHandlerDecorator customWebSocketHandlerDecorator(WebSocketHandler webSocketHandler) {
return new CustomWebSocketHandlerDecorator(webSocketHandler);
}
이제 마지막으로 Exception이 발생했을 때 ControllerAdvice처럼 예외 메시지를 처리해 줄 핸들러 매핑을 정의합니다.
@MessageExceptionHandler
@SendToUser("/queue/errors")
public String handleException(Throwable exception, StompHeaderAccessor stompHeaderAccessor) throws IOException {
if (exception instanceof WebsocketSecurityException ||
exception instanceof NotFoundWaitRoomException ||
exception instanceof NotFoundUserException) {
String sessionId = stompHeaderAccessor.getSessionId();
log.info("session = {}, connection remove", sessionId);
decorator.closeSession(sessionId);
}
else if (exception instanceof CommonException) {
return "server exception: " + exception.getMessage();
}
else {
String sessionId = stompHeaderAccessor.getSessionId();
decorator.closeSession(sessionId);
}
return "server exception: " + exception.getMessage() + "server session clear";
}
저는 WebsocketSecurityException 종류는 가장 큰 문제라 판단하여 세션을 종료하는 로직을 수행하도록 하였고,
그 외의 CommonException 종류에는 메세지를 전송하는 정도로 마치고 나머지는 전부 세션을 끝내는 것으로 하였습니다.
(세션은 종료하면 메시지가 전송되지 않는데 이 부분은 추후 다시 발전해 나가겠습니다.)
7. CORS / Security 설정
CORS는 Cross - Origin - Resource Sharing으로 웹 브라우저에서 실행되는 스크립트에서 다른 출처의 자원에 접근할 때 보안적인 문제를 다루는 메커니즘입니다. 만약 도메인이 다른 경우 CORS 문제로 인해 통신에 제약이 있을 수 있습니다. 따라서 API 서버 역할을 수행하는 백엔드는 CORS 설정으로 요청 가능한 도메인을 설정해야 합니다.
만약 외부 클라이언트의 직접 접근을 처리해야 한다면 allowedOriginPatterns 에 "*"와 같은 와일드카드를 생성하여 모든 도메인에 접근을 허용해야 합니다.
하지만 이는 보안에 취약점을 줄 수 있으므로 클라이언트의 직접 접근을 막고 중계 역할을 수행할 수 있는 프론트 서버를 중간에 두었습니다.
@Configuration
public class WebCorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOriginPatterns("http://localhost:8000", "http://localhost:3000", ---- 중략 ----)
.allowedMethods("*")
.allowedHeaders("*")
.exposedHeaders("Access-Control-Allow-Origin")
.allowCredentials(true);
}
}
로컬에서 gateway 역할을 수행하는 서버는 8000 포트, 프론트 서버는 3000번을 활용할 것이기 때문에 allowedOriginPatterns에 해당 주소를 입력하였습니다. 현재 OriginPatterns에는 제가 연결하고자 하는 로컬 서버와 AWS 서버의 도메인만 기록되어 있기 때문에 다른 Method (Get, Post 등), Header는 모두 와일드 카드로 설정하였고, exposeHeaders에 Access-Control-Allow-Origin을 추가하였습니다.
Spring Seurity는 정말 다루기 어렵지만 그만큼 뛰어난 보안성을 가지고 있습니다.
여기서 문제가 되는 부분은 소켓은 먼저 클라이언트 (여기서는 프론트 서버)와 백엔드 서버가 서로 3 - HandShake를 거친 후 응답이 처리되면 소켓 연결을 진행합니다. 이후 메시징 역할을 수행하는 STOMP 프로토콜로 애플리케이션 단에서 데이터를 처리합니다.
정리하면 Tcp(Http) -> Tcp(Socket) + Application(Stomp) 순서로 기동 되는 것입니다.
따라서, Spring Security에서 최초 연결 시에 Http를 처리할 수 있지만 이 부분은 다루기 복잡하다고 판단하여 websocket을 필요로 하는 엔드포인트에 대한 요청은 모두 통과시킨 후, 앞서 정의한 interceptor에서 애플리케이션 계층의 stomp 헤더를 검증하는 것으로 처리하였습니다.
(이 부분은 추후 다시 다루도록 하겠습니다.)
public static final List<String> AuthenticationGivenFilterWhitelist = Arrays.asList(
"/",
"/static/**",
"/favicon.ico",
"/wait-service/wait-websocket/**"
);private boolean isAuthorizationIssueRequired(String requestURI) {
return !FilterWhiteList.AuthenticationGivenFilterWhitelist.stream()
.anyMatch(uri -> antPathMatcher.match(uri, requestURI));
}antPathMatcher를 활용하여 wait-websocket으로 커넥션 요청이 들어오는 http는 모두 통과시키도록 처리하였습니다.
8. 테스트
길었던 Websocket 관련 로직 작성을 마쳤습니다. 언제나 그렇듯 가장 중요한 것은 작성이 아니라 테스트인 것 같습니다.
Websocket을 테스트하는 과정은 굉장히 까다롭습니다. 세션이 유지되는 것과 제거되는 점, 클라이언트에 전송되는 메시지 등을 판단해야 하기 때문입니다. 스프링에서 단위 테스트를 진행할 수 있지만, 프론트 서버 -> 게이트웨이 -> 백엔드 연결되는 과정을 눈으로 직접 확인해보기 위해 간단하게 vue.js로 프론트 서버를 구축하고 테스트를 진행하도록 하겠습니다.
먼저, 현재 프로젝트는 MSA의 wait-server를 담당하고 있지만 인증 토큰 생성은 member-server에서 생성하고 있습니다.
테스트를 위해 member-server를 매번 기동하여 토큰 발급 처리하기 어려움으로 스프링에서 InitDB 클래스를 생성한 후
더미 데이터를 추가하였습니다. @PostConstruct는 모든 스프링빈이 등록되고 의존관계 주입을 마친 후에 해당 메서드가 실행될 수 있도록 처리해 주는 어노테이션입니다.
@Component
@RequiredArgsConstructor
public class InitDb {
private final InitService initService;
@PostConstruct
public void init() {
initService.dbInit();
}
@Slf4j
@Component
@Transactional
@RequiredArgsConstructor
static class InitService {
private final EntityManager em;
private final WaitRoomFacadeService waitRoomFacadeService;
--- 중략 ---
저는 프론트 서버는 테스트용 정도밖에 다뤄본 경험이 없어서 최대한 로직은 간단하게 Vue.js로 작성하였습니다.
<index.js>
module.exports = {
dev: {
// Paths
assetsSubDirectory: 'static',
assetsPublicPath: '/',
proxyTable: {
'/api': {
target: 'http://localhost:8000',
// changeOrigin: true,
pathRewrite: {
'^/api': ''
}
}
},
host: 'localhost', // can be overwritten by process.env.HOST
port: 3000, // can be overwritten by process.env.PORT, if port is in use, a free one will be determined
autoOpenBrowser: false,
errorOverlay: true,
notifyOnErrors: true,
proxyTable에 등록된 target은 '/api'라는 prefix 요청에 대해 해당 타깃으로 보내겠다는 의미입니다.
저는 client -> front 중계 -> 백엔드 스프링 클라우드 gateway 중계 -> 실제 서비스를 호출하는 방식으로 구현하고 있어서
gateway 서버를 target으로 설정하였습니다.
< WaitRoomSocket.vue>
methods: {
connect () {
const accessToken ='Bearer eyJhbGciOiJIUzUxMiJ9FUiJd' --- 중략 ---
const refreshToken ='eyJhbGciOiJIUzUxMiJ9.IRdLQw' --- 중략 ---
const userId = 'c87afd49-956f-4e4c-9829-f2f24a193695'
const socket = new SockJS('/api/wait-service/wait-websocket', {}, {transports: ['websocket', 'xhr-streaming', 'xhr-polling']})
// const socket = new WebSocket('/api/wait-service/wait-websocket')
this.stompClient = Stomp.over(socket)
this.stompClient.heartbeat.outgoing = 0 // 클라이언트가 서버로 하트비트를 보낼 간격(밀리초)
this.stompClient.heartbeat.incoming = 0
const waitRoomId = this.channel
const headers = {
'Authorization': accessToken,
'RefreshToken': refreshToken,
'UserId': userId,
'WaitRoomId': waitRoomId,
'destination': `/wait-service/waitroom/sub/${waitRoomId}/join`
}
console.log(`/api/wait-service/waitroom/sub/${waitRoomId}/join`)
console.log('waitRoomId = ', waitRoomId)
this.stompClient.connect(headers, (frame) => {
console.log('frame = ', frame)
this.stompClient.subscribe(
`/wait-service/waitroom/sub/${waitRoomId}/join`, (chatMessageResponse) => {
console.log('log', JSON.stringify(chatMessageResponse))
}, (error) => {
console.log(error)
})
this.stompClient.subscribe(
`/user/queue/errors`, headers, (chatMessageResponse) => {
console.log('log', JSON.stringify(chatMessageResponse))
}, (error) => {
console.log(error)
})
this.stompClient.send(`/wait-service/waitroom/pub/${waitRoomId}/join`, headers,
JSON.stringify({
userId: userId,
roomId: waitRoomId
}))
})
this.connected = true
},
disconnect () {
if (this.stompClient !== null) {
this.stompClient.disconnect()
}
this.connected = false
console.log('Disconnected')
},
showGreeting (message) {
this.greetings.push(message)
}
}
}
순서는 stompClient(Stomp)로 커넥트를 요청한 후, 연결이 되면 콜백으로 subscribe로 메시지 브로커에 등록된 토픽을 구독하고, 서버로 send 요청을 수행하여 필요한 정보를 전달하는 코드입니다.
즉 순서는 connect -> 메시징 구독 -> 메시지 전송으로 이뤄지며 백엔드에서 stomp 헤더를 파싱 하여 인증 정보를 처리하므로
Stomp에 헤더 정보를 추가하였습니다.
(token 관련 인증 정보는 간단하게 String으로 처리하였습니다.)
이제 각 의존성이 있는 서버들을 기동한 후, 테스트를 진행하겠습니다.
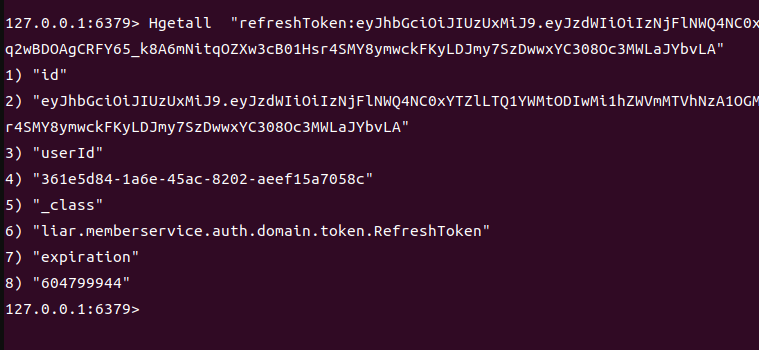
InitDb로 http로 접근하여 waitRoom을 생성하는 로직을 수행하였고 redis에 다음과 같이 값이 입력되었습니다.

localhost:3000/waitroom url에 접근하여 방금 등록한 waitRoomId를 입력한 후, connect를 누르고 개발자 모드를 확인하면 같은 결과가 나옵니다.

최초 webSocket에 연결이 connect 되면, destination에 대한 구독을 실행하고 Send로 자신의 userId와 waitRoomId를 등록하여 해당 방 참여에 대한 메시지를 전달합니다.
<Interceptor 통과>

<Handler 적용>

<정상 요청 응답 >
(이전 세션이 종료되어서 서버를 다시 기동하여 waitRoomId가 바뀐 것입니다.!!!)

<Redis에 저장되지 않은 WaitRoom에 접속 혹은 잘못된 헤더 정보>


로그를 보면, WebsocketSecurityException이 터지면서 connection이 remove 되었습니다.
개발자 도구로 확인해 보아도 클라이언트의 커넥션이 종료되었습니다.!

<Dto의 userId와 waitRoomId가 헤더 정보와 다른 경우>
this.stompClient.send(`/wait-service/waitroom/pub/${waitRoomId}/join`, headers,
JSON.stringify({
userId: 'wrong !!!',
roomId: waitRoomId
}))
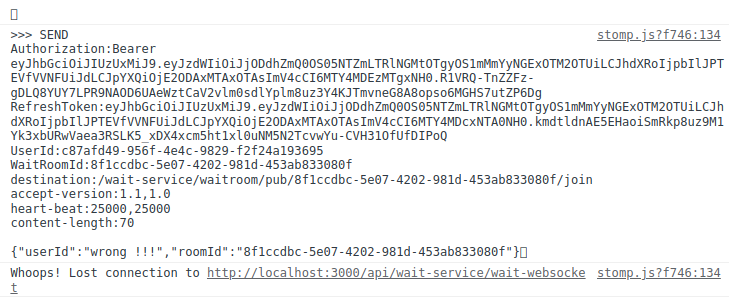
모든 테스트를 성공하였습니다 ㅎㅎㅎ ㅠㅠ!!
9. 정리하며...
그 어느 때보다, 정리하며...를 적고 싶었던 시간이었습니다.. ㅎㅎ
거의 30시간 가까이 에러를 맞이하며 수정하고 디버깅하고 다시 해결하고 에러나고의 반복이었던 것 같습니다.
이전에 webSocket을 연결하는 간단한 실습을 한 적이 있었는데, 그 당시에는 여러 비즈니스 로직이 없는
간단한 서버사이드 렌더링으로 채팅방을 구현하는 것이었습니다.
이번에는 SpringSecurity, Interceptor, 예외처리를 추가하고 스프링 부트의 최신 버전으로 적용하다보니 정말 많은 에러를 맞이할 수 있었습니다. 에러가 발생하니 이전에 쉽게 지나갔던 부분을 다시 검토할 수 있게 되었고 정말 깊게 스프링의 내부 구조와 우원리를 다시 한번 볼 수 있게 된 계기가 되었습니다.
이번 Websocket에 여러 가지 기능을 붙이며, 소켓이 어떻게 전송이 되는지부터 시작해서 Spring이 어떻게 websocket을 지원하고 있는지, 그리고 에러가 생기면 어떻게 세션을 종료하는지 등을 정말 깊게 공부할 수 있었던 것 같습니다.
또한, 정말 자바 스프링의 위대함을 다시 한번 느낄 수 있었습니다.
혹시 "WebsocketSession 인터페이스를 활용하는 구현체를 찾아서 custom 하게 바꾼 후 빈을 등록하면 되지 않을까?"
라는 생각을 가지고 접근을 하니 이러한 생각을 현실로 만들 수 있도록 모든 것을 제공해 주는 스프링에 대해서
다시 한번 감사함을 느낄 수 있었습니다.

정말 스프링 프레임워크가 발전하고 많은 레퍼런스를 볼 수 있도록 힘 써주신 선임 개발자님들 감사드립니다 ㅠㅠㅠㅠㅠㅠㅠ
긴 글이었지만 읽어주셔서 감사드립니다.!
'SpringBoot' 카테고리의 다른 글
| [SpringBoot] 리플리카 데이터베이스 연동하기 (0) | 2023.06.11 |
|---|---|
| [SpringBoot] 의존성 주입과 Profile로 Filter 설정 동적 변경하기 (0) | 2023.04.01 |
| [SpringBoot] 더미 데이터로 실행 계획 살펴보기 (QueryDsl) (0) | 2023.03.24 |
| [SpringBoot] 중복 로그인 처리 (비즈니스 로직과 IP 차단) (1) | 2023.03.22 |
| [SpringBoot] SpringRestDocs 활용하기 (1) | 2023.03.19 |