안녕하세요. GoseKose입니다.
이번 포스팅은 CircuitBreaker, Cache, 외부 스토리지를 활용하여 첨부파일 관리하는 과정을 작성하도록 하겠습니다.
1. 목표 시나리오

첨부파일을 업로드할 때, 두 가지 주요 방법이 있습니다:
- Client -> Server로 MultipartFile을 업로드:
- 이 방법은 클라이언트가 파일을 서버로 전송하고, 서버가 이 파일을 스토리지에 저장합니다.
- 장점: 서버가 파일 업로드와 저장을 관리하므로 보안과 검증이 용이합니다.
- 단점: 서버에 부하가 증가하고, 대규모 파일 업로드 시 성능 문제가 발생할 수 있습니다.
- 클라이언트가 직접 스토리지에 파일을 업로드:
- 클라이언트가 직접 외부 스토리지에 파일을 업로드합니다.
- 장점: 서버 부하를 줄일 수 있으며, 클라이언트가 직접 스토리지에 접근하여 빠른 업로드가 가능합니다.
- 단점: 클라이언트가 스토리지에 직접 접근할 수 있어 보안 문제가 발생할 수 있습니다.
이를 해결하기 위해 클라우드 서비스 제공업체는 Presigned URL을 제공합니다.
Presigned URL은 클라이언트가 지정된 시간 동안 외부 스토리지에 직접 파일을 업로드하거나 다운로드할 수 있도록 임시 권한을 부여하는 URL입니다. 이를 통해 보안 문제를 해결하면서도 서버 부하를 줄일 수 있습니다.
따라서, 목표 시나리오는 Presigned URL을 활용하여 외부 스토리지인 Amazon S3, Google Cloud Service에 첨부파일을 관리하는 것으로 진행하였습니다.
2. 아키텍처 구성
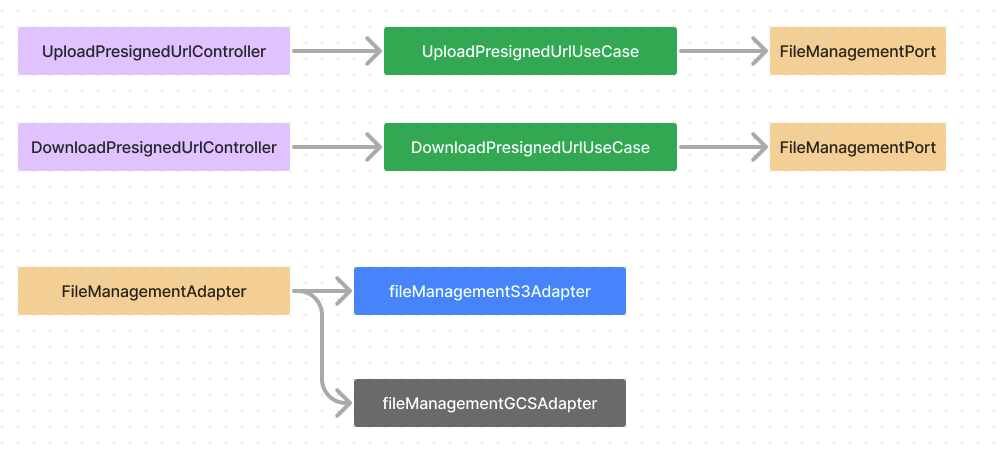
구조는 Controller / UseCase / Port로 구성할 수 있습니다.
외부 스토리지를 두 개 활용할 예정이므로 구현체로 S3Adapter, GCSAdapter를 만들 예정이고,
이 두 가지를 어댑터 패턴으로 분기할 Adapter 총 3가지로 구성합니다.
3. 가용성을 위한 서킷브레이커 활용하기
위의 아키텍처에서 두 가지 외부 스토리지를 활용하는 이유는 가용성을 높이기 위함입니다.
특정 클라우드 서비스에 파일을 업로드하려는 요청에 문제가 생기면, 다른 서비스를 활용하여 이를 대체할 수 있도록
구성할 수 있습니다. try - catch로 분기하는 코드를 작성할 수 있지만, 시스템 안정성을 높이는 방법으로
SpringBoot는 CircuitBreaker라는 라이브러리를 제공합니다. 서킷 브레이커는 다음의 특징을 가지고 있습니다.
| 특징 | 설명 |
| 가용성 유지 | 외부 서비스나 데이터베이스가 일시적으로 불안정할 때 서킷 브레이커가 이를 감지하고 호출을 차단 |
| 시스템 안정성 | 장애가 발생한 서비스에 대한 반복적인 호출을 방지 |
| 예외 전파 방지 | 예외가 전체 애플리케이션에 전파되는 것을 방지 |
| 동작 방식 | 설명 |
| Closed | 모든 요청이 정상적으로 처리, 실패율이 일정 임계값을 초과하지 않으면 상태 유지 |
| Open | 실패율이 임계값을 초과하면 서킷 브레키어 동작 / 모든 요청 차단 |
| Half-Open | 일정 시간이 지난 후, 일부 요청을 허용하여 시스템이 회복되었는지 확인 |
이러한 특징으로 서킷브레이커를 사용하면
default로 사용하는 Amazon S3에 문제가 생기면, GCS Adapter로 fallback 처리할 수 있도록 구성할 수 있습니다.

4. 캐싱 활용하기
하나의 파일을 업로드할 때는 일회성 요청인 경우가 많지만, 다운로드는 반복 작업이 수행될 수 있습니다.
매 다운로드 요청마다 PresignedURL을 만들경우 , 성능 문제가 발생할 수 있습니다.
만약 다운로드 요청이 왔을 때 PresignedURL을 생성하고, 일정 시간 동안 캐싱한다면 성능 및 네트워크 비용 문제를 줄일 수 있습니다.

SpringBoot에서는 AOP와 Redis를 활용하여,
캐시와 관련된 횡단 관심사를 분리하면서, 키가 존재하면 캐싱된 정보를 가져오도록 구성할 수 있습니다.
5. 코드 구성하기
- Upload를 위한 PresignedUrl Controller
@RestController
class GenerateFileUploadPresignedUrlRestController(
private val generateFileUploadPresignedUrlUseCase: GenerateFileUploadPresignedUrlUseCase,
) {
@GetMapping("/api/v1/files/presignedUrl/upload")
fun generatePresignedUrl(
@RequestHeader("memberId") memberId: Long,
@RequestParam fileName: String,
): PresignedUrlMetadataHttpResponse {
return generateFileUploadPresignedUrlUseCase.generateFileUploadPresignedUrl(
GenerateFileUploadPresignedUrlUseCase.Command(
memberId = memberId,
fileName = fileName,
),
).let(PresignedUrlMetadataHttpResponse::from)
}
}
- Upload를 위한 PresignedUrl UseCase
@Service
class GenerateFileUploadPresignedUrlService(
private val fileMetadataSaver: FileMetadataSaver,
private val fileManagementPort: FileManagementPort,
) : GenerateFileUploadPresignedUrlUseCase {
override fun generateFileUploadPresignedUrl(command: GenerateFileUploadPresignedUrlUseCase.Command): PresignedUrl {
val (memberId, fileName) = command
val fileMetadata = fileMetadataSaver.save(FileMetadata.of(memberId, fileName))
val presignedUrl =
fileManagementPort.generateFileUploadPresignedUrl(
fileKey = fileMetadata.fileKey,
durationMillis = DURATION_MILLIS,
)
fileMetadataSaver.save(fileMetadata.registerVendor(presignedUrl.vendor))
return presignedUrl
}
companion object {
private const val DURATION_MILLIS = 1000 * 60 * 10L // 10분
}
}
- CircuitBreaker를 적용한 FileManagementPort 구현체
@Primary
@Component
class FileManagementAdapter(
@Qualifier("fileManagementS3Adapter") private val s3Adapter: FileManagementS3Adapter,
@Qualifier("fileManagementGCSAdapter") private val gcsAdapter: FileManagementGCSAdapter,
circuitBreakerFactory: CircuitBreakerFactory<*, *>,
) : FileManagementPort {
private val circuitBreaker = circuitBreakerFactory.create("s3CircuitBreaker")
private val logger = LoggerFactory.getLogger(FileManagementGCSAdapter::class.java)
override fun generateFileUploadPresignedUrl(
fileKey: String,
durationMillis: Long,
): PresignedUrl {
return circuitBreaker.run({
logger.info("s3 Adapter Try")
s3Adapter.generateFileUploadPresignedUrl(fileKey, durationMillis)
}, { throwable ->
logger.error("s3 Adapter Exception = [${throwable.message}]")
logger.info("gcs Adapter Try")
gcsAdapter.generateFileUploadPresignedUrl(fileKey, durationMillis)
})
}
override fun generateFileDownloadPresignedUrl(
fileKey: String,
vendor: FileMetadata.Vendor,
durationMillis: Long,
): PresignedUrl {
return when (vendor) {
FileMetadata.Vendor.S3 -> s3Adapter.generateFileDownloadPresignedUrl(fileKey, durationMillis)
FileMetadata.Vendor.GCS -> gcsAdapter.generateFileDownloadPresignedUrl(fileKey, durationMillis)
}
}
}
- Download를 위한 PresignedUrl Controller
@RestController
class GenerateFileDownloadPresignedUrlRestController(
private val generateFileDownloadPresignedUrlUseCase: GenerateFileDownloadPresignedUrlUseCase,
) {
@GetMapping("/api/v1/files/{fileId}/presignedUrl/download")
fun generatePresignedUrl(
@RequestHeader("memberId") memberId: Long,
@PathVariable("fileId") fileId: Long,
): PresignedUrlMetadataHttpResponse {
return generateFileDownloadPresignedUrlUseCase.generateFileDownloadPresignedUrl(
GenerateFileDownloadPresignedUrlUseCase.Command(
fileId = fileId,
),
).let(PresignedUrlMetadataHttpResponse::from)
}
}
- Download를 위한 PresignedUrl Service
@Service
class GenerateFileDownloadPresignedUrlService(
private val fileMetadataReader: FileMetadataReader,
private val fileManagementPort: FileManagementPort,
) : GenerateFileDownloadPresignedUrlUseCase {
@CacheableAnnotation("presignedUrlDownloadCache", key = "#command.fileId", durationMillis = 1000 * 60 * 9L)
override fun generateFileDownloadPresignedUrl(command: GenerateFileDownloadPresignedUrlUseCase.Command): PresignedUrl {
val fileMetadata = fileMetadataReader.getByIdOrNull(command.fileId).notnull()
val vendor = fileMetadata.vendor
requireBusiness(vendor != null, BusinessErrorCause.NOT_FOUND)
return fileManagementPort.generateFileDownloadPresignedUrl(
fileKey = command.fileId.toString(),
vendor = vendor,
durationMillis = DURATION_MILLIS,
)
}
companion object {
private const val DURATION_MILLIS = 1000 * 60 * 10L // 10분
}
}
- AOP를 활용한 횡단 관심사 분리 및 캐싱
@Aspect
@Component
class CacheableAspect(
private val cacheManagementPort: CacheManagementPort,
) {
private val parser = SpelExpressionParser()
@Around("@annotation(cacheableAnnotation)")
fun around(
joinPoint: ProceedingJoinPoint,
cacheableAnnotation: CacheableAnnotation,
): Any? {
val key = "${cacheableAnnotation.cacheName}:${generateKey(joinPoint, cacheableAnnotation)}"
val cachedValue = cacheManagementPort.get(key, PresignedUrl::class.java)
if (cachedValue != null) {
return cachedValue
}
return joinPoint.proceed().apply {
cacheManagementPort.set(key, this, cacheableAnnotation.durationMillis)
}
}
private fun generateKey(
joinPoint: ProceedingJoinPoint,
cacheableAnnotation: CacheableAnnotation,
): String {
val method =
joinPoint.signature.declaringType.getDeclaredMethod(
joinPoint.signature.name,
*joinPoint.args.map { it::class.java }.toTypedArray(),
)
val context = StandardEvaluationContext()
method.parameters.forEachIndexed { index, parameter ->
context.setVariable(parameter.name, joinPoint.args[index])
}
val expression = parser.parseExpression(cacheableAnnotation.key)
return requireNotNull(expression.getValue(context)).toString()
}
}
- Redis를 활용한 CacheManagementPort 구현체
@Component
class RedisCacheManagementAdapter(
private val redisTemplate: StringRedisTemplate,
) : CacheManagementPort {
override fun <T> get(
key: String,
type: Class<T>,
): T? {
val value = redisTemplate.opsForValue()[key]
return value?.parseJson(type)
}
override fun <T> set(
key: String,
value: T,
durationMillis: Long,
) {
redisTemplate.opsForValue().set(key, requireNotNull(value).toJson(), Duration.ofMillis(durationMillis))
}
}
6. 추가로 고려할 점
파일을 업로드하는 PresignedURL 생성은 서킷 브레이커로 장애 전파를 줄이고 가용성을 늘릴 수 있지만,
다운로드를 위한 PresignedURL을 요청할 경우에는 파일이 업로드된 곳에 요청을 해야 합니다.
따라서, 파일을 다수의 스토리지에 백업하는 배치를 돌리는 방법으로 가용성을 높이는 방법을 적용할 수 있습니다.
다음 포스팅은 서킷 브레이커에 대해서 깊게 정리하는 과정을 작성하도록 하겠습니다.
긴 글 읽어주셔서 감사합니다!
'SpringBoot' 카테고리의 다른 글
| [SpringBoot] Spring Batch Partition 단위로 병렬 처리하기 (0) | 2024.06.29 |
|---|---|
| [SpringBoot] Kotest 멀티모듈 컨트롤러 테스트 (0) | 2023.11.06 |
| [SpringBoot] SpringBoot Jpa save() (1) | 2023.10.28 |
| [SpringBoot] 리플리카 데이터베이스 연동하기 (0) | 2023.06.11 |
| [SpringBoot] 의존성 주입과 Profile로 Filter 설정 동적 변경하기 (0) | 2023.04.01 |