안녕하세요. 회사와 함께 성장하고 싶은 KOSE입니다.
이번 포스팅은 백준 스택 문제 히스토그램 자바 풀이를 진행하도록 하겠습니다.
문제 출처: https://www.acmicpc.net/problem/1725
1725번: 히스토그램
첫 행에는 N (1 ≤ N ≤ 100,000) 이 주어진다. N은 히스토그램의 가로 칸의 수이다. 다음 N 행에 걸쳐 각 칸의 높이가 왼쪽에서부터 차례대로 주어진다. 각 칸의 높이는 1,000,000,000보다 작거나 같은
www.acmicpc.net
1. 풀이 소스
import java.io.*;
import java.util.*;
import static java.lang.Integer.parseInt;
public class Main {
static int n;
static int[] histogram;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
n = parseInt(br.readLine());
histogram = new int[n];
for (int i = 0; i < n; i++) histogram[i] = parseInt(br.readLine());
sb.append(getArea());
System.out.println(sb);
}
static int getArea() { // 최대 20억을 넘지 않음
Stack<Integer> stack = new Stack<>();
int area = 0; // 20억을 넘지 않음
for (int i = 0; i < n; i++) {
// 스택이 비지 않고 인덱스의 값이 peek의 히스토그램 값보다 작거나 같다면
while (!stack.isEmpty() && histogram[stack.peek()] >= histogram[i]) {
int h = histogram[stack.pop()];
// 스택이 비어 있다면 길이는 i, 스택이 있다면 현재 위치에서 stack의 인덱스
int w = stack.isEmpty() ? i : i - 1 - stack.peek();
area = Math.max(area, h * w);
}
stack.push(i);
}
// stack에 남아있는거 전부 제거하며 다시 업데이트
while(!stack.isEmpty()) {
int h = histogram[stack.pop()];
int w = stack.isEmpty() ? n : n - 1 - stack.peek();
area = Math.max(area, h * w);
}
return area;
}
}
2. 풀이 중점 사항
해당 문제는 매우 어려웠던 문제로 하단의 블로그를 참고하였습니다.
stack에 값을 빼서, 면적을 구해야 하는 과정은 이해가 되었지만 도중에 높이가 0이 오는 경우에는 어떻게 해야 하는가?
라는 물음에 빠지면서, 많은 시간을 소비하였습니다.
// 스택이 비지 않고 인덱스의 값이 peek의 히스토그램 값보다 작거나 같다면
while (!stack.isEmpty() && histogram[stack.peek()] >= histogram[i]) {
int h = histogram[stack.pop()];
// 스택이 비어 있다면 길이는 i, 스택이 있다면 현재 위치에서 stack의 인덱스
int w = stack.isEmpty() ? i : i - 1 - stack.peek();
area = Math.max(area, h * w);
}
stack.push(i);
현재 있는 인덱스의 값보다 스택에 있는 높이가 높거나 같다면, 스택에서 빼면서 면적을 구하는 코드입니다.
위에 있는 코드는 다음과 같은데, 그림과 함께 설명하도록 하겠습니다.

예시는 7개의 입력과 4 2 1 2 0 2 1의 높이로 구성되어 있는 히스토그램입니다.
빨간색 화살표는 인덱스, 초록색 화살표는 스택의 peek입니다.
시작 인덱스 0은 stack.isEmpty()이므로 인덱스를 추가합니다.

스택에 있는 높이는 4인데, 인덱스 1에 있는 높이는 2입니다. 따라서 스택에 있는 0을 빼서 면적을 구해야 합니다.
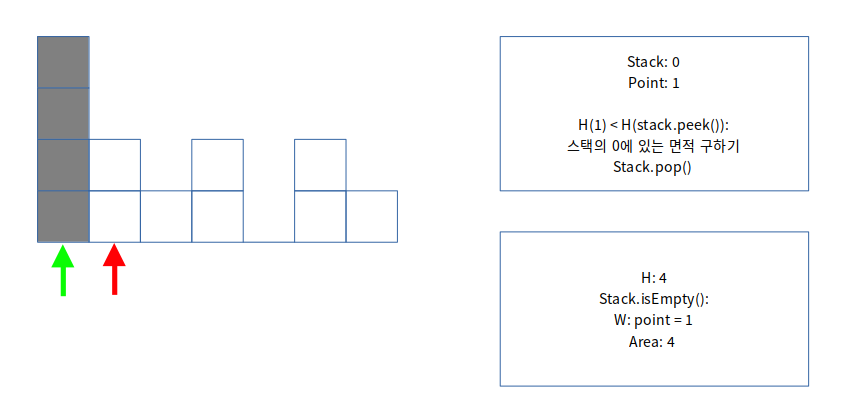
stack이 비어 있으므로, 인덱스 길이만큼을 w로 설정합니다.
Area = 4입니다.
스택에 인덱스 1을 추가합니다.

스택에 있는 peek는 1이고, 그것의 높이는 2입니다. 반면 포인터의 위치의 높이는 1이므로
스택 1에 대한 면적을 구합니다.

스택이 비어있으므로, 인덱스 길이만큼 너비를 설정합니다. (스택의 너비를 인덱스 길이만큼 구하는 이유는 다음과 같이 연속된 같은 높이를 가지는 블록의 면적을 모두 고려하기 위함입니다.)

stack에 있는 인덱스 2의 높이보다 인덱스 3의 높이가 더 크므로 진행합니다.
같은 방법으로, 인덱스 4 이전에 쌓였던 스택을 모두 제거하며 면적을 구합니다.
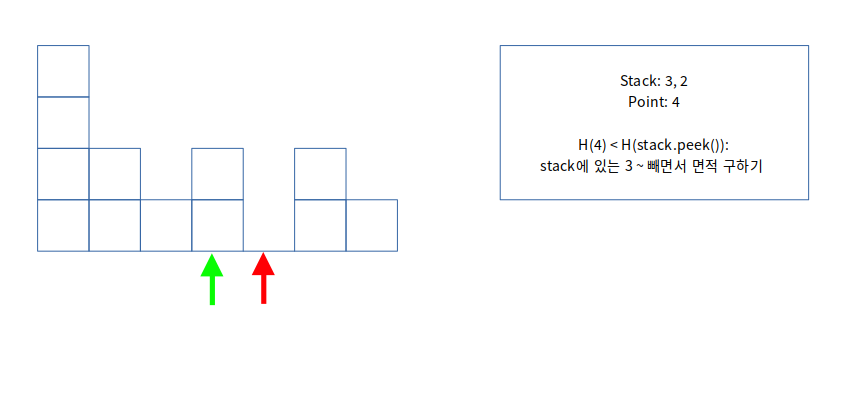

여기서 중요한 부분은, 현재 포인터 위치 - 1 - 스택의. peek() 값만큼 너비를 선택해야 합니다.
그 이유는 stack.peek()는 경계를 설정하는 부분이고, 다음 스택에 값이 있으니 그 이전까지 면적을 구해야 합니다.
포인터의 길이는 항상 스택에 있는 값보다 +1 이상이 더 큽니다.
즉 point - 1은 너비의 가장 오른쪽의 끝점을 의미하고, stack.peek()는 시작하는 위치라고 생각하면,
(2, 3)의 넓이이므로 1이 도출되게 되는 것입니다. 이것을 한 번에 계산하기 위해 3 - 2 = point - 1 - stack.peek()가 도출됩니다.
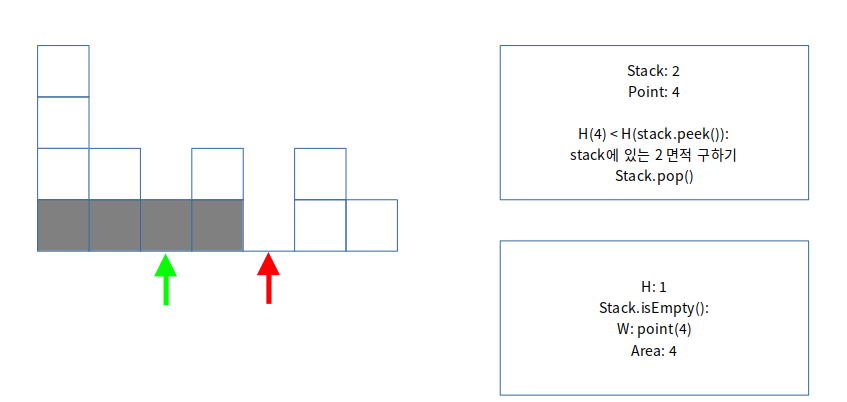
이어서, 스택이 비어있으므로 point의 인덱스 값을 너비로 설정하여 면적을 구합니다.
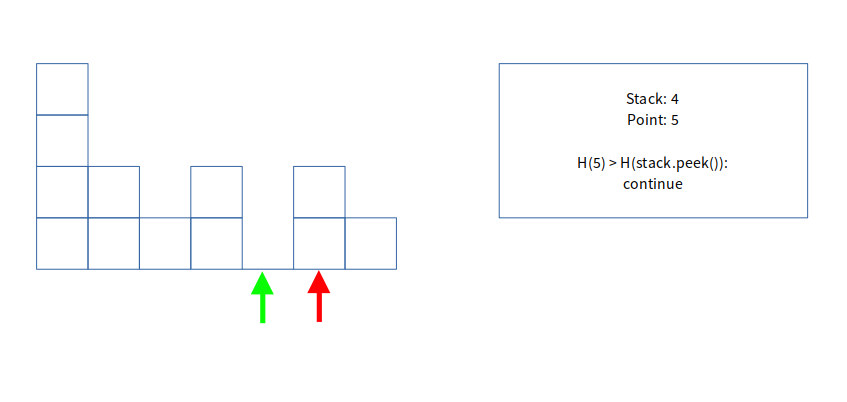


제가 어려웠던 부분은 이처럼 0이 도중에 나오는 경우 어떻게 해결해야 하는가? 였습니다.
하지만 이전에 설정한 범위를 생각해 보면, while루프는 stack.peek()의 값이 히스토그램의 값보다 크거나 같을 때
면적을 계산합니다. 즉, stack.peek()이 0이 된다면, 다시 0이 나오기 전까지 그 상태가 유지되는 것입니다.
(ex 0 2 1 3 4 --> 이렇게 유지될 경우 0보다 같거나 작은 수는 없으니 stack에 0은 그대로 유지)
따라서, 이처럼 0을 가진 h의 높이가 stack.peek()로 경계를 만들어주고 있는 것을 볼 수 있습니다.

마지막은 이처럼 stack에 0이 쌓여 있는 경우, 혹은 계속 상승하는 상태여서 stack에서 나오지 않는 경우가 있을 수 있습니다.
따라서, 스택에서 값을 빼며 면적을 다시 구합니다.


이를 통해 가장 큰 면적 4를 구할 수 있습니다.
이상으로 히스토그램 자바 풀이를 마치도록 하겠습니다.! 감사합니다.!
참조 블로그: https://st-lab.tistory.com/255
[백준] 6549번 : 히스토그램에서 가장 큰 직사각형 - JAVA [자바]
https://www.acmicpc.net/problem/6549 6549번: 히스토그램에서 가장 큰 직사각형 입력은 테스트 케이스 여러 개로 이루어져 있다. 각 테스트 케이스는 한 줄로 이루어져 있고, 직사각형의 수 n이 가장 처음
st-lab.tistory.com
'Algorithm' 카테고리의 다른 글
| [Algorithm] 백준 이분탐색 문제 - 공유기 설치(2110) 자바 풀이 (0) | 2023.05.24 |
|---|---|
| [Algorithm] 백준 이분탐색 문제 - 나무 자르기(2805) 자바 풀이 (0) | 2023.05.23 |
| [Algorithm] 백준 문자열 문제 - 무한 문자열(12871) 자바 풀이 (0) | 2023.05.23 |
| [Algorithm] 백준 문자열 문제 - 여우는 어떻게 울지?(9536) 자바 풀이 (0) | 2023.05.23 |
| [Algorithm] 백준 유니온파인드 문제 - 친구 네트워크(4195) 자바 풀이 (0) | 2023.05.23 |



















