안녕하세요. 회사와 함께 성장하고 싶은 KOSE입니다.
이번 포스팅은 칼럼형 DBMS와 로그형 DBMS를 비교하는 글을 작성하고자 합니다.
데이터베이스의 필드는 행과 열의 교차점이며 특정 자료형의 단일 값 입니다.
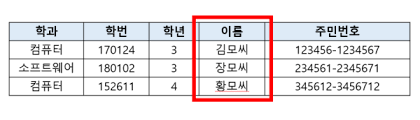
'김모씨'는 첫 번째 행의 '이름'이라는 varchar(varchar2) 특정 자료형을 가진 값의 필드가 되는 것입니다. 데이터베이스는 디스크에 저장하는 방식에 따라, 칼럼형 DBMS와 로우형 DBMS로 나눌 수 있습니다.
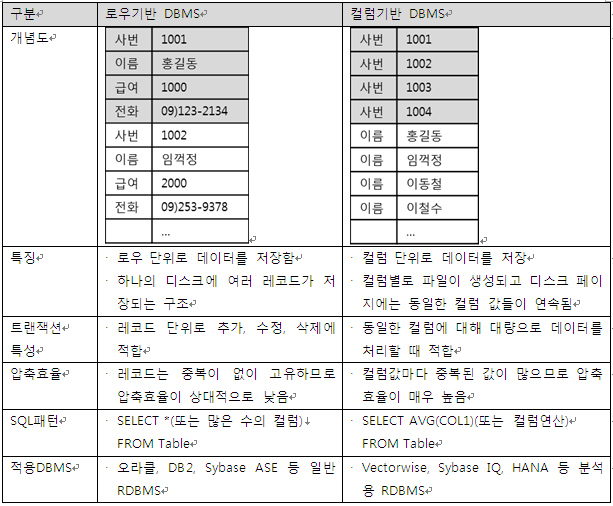
1. 로우형 데이터베이스
| 001 | 1001 | KOSE | 123-123 |
| 002 | 1002 | GOSE | 123-123 |
로우형 데이터베이스는 전통적인 DBMS 구조로 여러 필드의 값은 고유 식별 키로 구분할 수 있는 레코드 형식에 적합합니다. 특정 사용자의 요청이 여러 컬럼을 포함하는 데이터를 요구한다면 이러한 로우형 데이터베이스가 적합할 수 있습니다.
로우형 데이터베이스에 적합한 상황은 무엇일까?
특정 인덱스로 학교 정보를 가져와야 한다고 생각해 보겠습니다.
select * from Schools where school_id = 10;이 경우, 인덱스 10인 학교 로우 데이터를 읽게 됩니다. 이때 발생하는 이점이 공간 지역성입니다. 공간 지역성이란 a[0], a[1] 처럼 같은 데이터 배열에 연속적으로 접근할 때 참조된 데이터 근처에 있는 데이터가 잠시 후 사용될 가능성이 높은 것입니다. 하나의 로우에 데이터를 저장하므로, 행 단위의 데이터 요청이 많은 상황이라면 로우형 데이터가 유리할 수 있습니다.
2. 칼럼형 데이터베이스
칼럼형 데이터베이스는 데이터를 로우 단위가 아니라 수직 분할하여 저장합니다. 로우를 연속해 저장하는 방식과 달리 같은 칼럼끼리 디스크에 연속해 저장하는 방식입니다. 장점은, 특정 컬럼만 따로 읽는 경우가 많은 경우, 해당 데이터를 로우 단위로 읽지 않으므로 칼럼별로 파일을 저장하거나 세그먼트 단위로 저장하면 효율성을 높일 수 있습니다.
효율성이 증가하는 이유는 무엇일까?
사번: 1000:001,003,2000:002,3000:004
- 같은 칼럼의 여러 값을 한 번에 읽으면 캐시 활용도와 처리 효율성이 높아집니다. 최근 CPU는 벡터 연산을 통해 한 번의 CPU 명령으로 많은 데이터를 처리할 수 있습니다.
- 자료형 별로 저장하면 압축률도 증가합니다. 각 컬럼마다 타입에 맞는 적절한 압축 알고리즘을 적용할 수 있습니다.
- 한 컬럼의 데이터를 직렬화하여 저장하여 로우 방식과 다르게 데이터를 PK로 설정하여 데이터에 매칭되는 값을 포인터로 설정하여 데이터를 처리합니다.
3. 데이터 베이스 효율적인 저장 방식
로그를 남겨야 하는 시스템과 (WAL, Write ahead logging)과 다중 동시성 제어(Multiversion concurrency control)가 필요한 온라인 트랜잭션 처리 시스템(OLTP) 성 업무는 로우 기반의 시스템으로 구현하는 것이 적합합니다.
성능을 높이기 위해서는 파티셔닝과 인덱스, 캐싱을 활용해야 하고 별도의 온라인 분석 처리 데이터베이스 (OLAP)를 적용하는 방법을 강구해야 합니다.
[다중 동시성 제어 시스템이 로우형 데이터 베이스가 적합한 이유는 무엇일까?]
MVCC는 동시 접근을 허용하는 데이터베이스에서 동시성을 제어하기 위해 사용하는 방법 중 하나입니다.
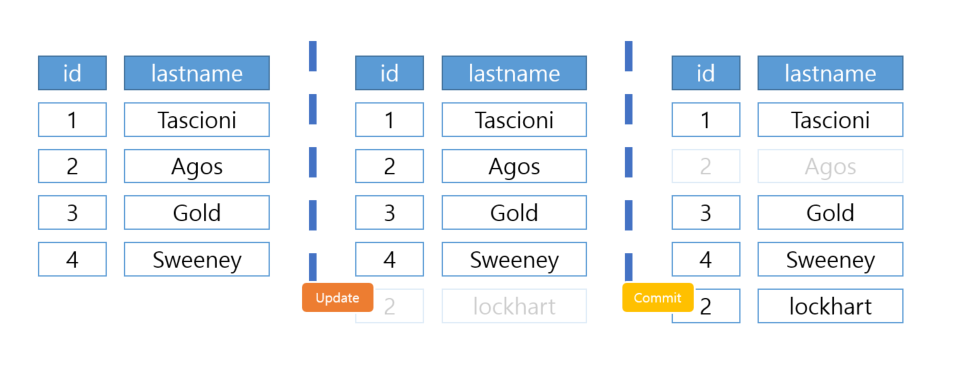
MVCC 모델에서 데이터에 접근하는 사용자는 접근한 시점에서 데이터베이스의 SnapShot을 읽습니다. Snapshot에 대한 데이터 변경이 완료될 때까지 만들어진 변경사항은 다른 데이터 베이스 사용자가 볼 수 없습니다. 사용자가 데이터를 업데이트하면 이전의 데이터를 덮어 씌우는 것이 아니라 새로운 버전의 데이터를 UNDO 영역에 생성합니다. 이후, 이전 데이터와 비교하여 변경된 내용을 기록합니다. 사용자는 마지막 버전의 데이터를 읽게 됩니다.
로우형 데이터베이스는 하나의 행에 대한 데이터를 연속된 시퀀스로 기록하기 때문에 다중 동시성 제어 시스템에서는 특정 값이 바뀔 경우 해당 로우 전체를 최신 버전의 데이터를 UNDO 영역에 생성하는 것입니다. 따라서, 컬럼형에 비해 속도가 빠를 수 있습니다.
<추가>
PostGreSqL은 주기적으로 VACUUM 하여 기존 데이터에 대한 처리를 진행
Oracle은 Rollback segment 방식을 활용하여 업데이트된 데이터를 새롭게 변경하고
이전 데이터는 Rollback segment에 보관하는 방식을 따릅니다.
참조: https://dataonair.or.kr/db-tech-reference/d-lounge/expert-column/?mod=document&uid=52606
'DB' 카테고리의 다른 글
| [DB] MySQL8.x 리플리카 서버 적용하기(1) (0) | 2023.06.10 |
|---|---|
| [DB] 락(잠금) (0) | 2023.04.24 |
| [DB] MySQL8.0 Index (0) | 2023.02.06 |
| [DB] MySQL 엔진 아키텍처 (Real MySQL 8.0) (0) | 2023.01.22 |
| [DB] MySQL 계정 생성 및 권한 부여 (Real MySQL 8.0) (0) | 2023.01.07 |