안녕하세요. 기술적 겸손함으로 회사와 함께 성장하고 싶은 KOSE입니다.
이번 포스팅은 리플리카 서버를 적용하는 일련의 과정을 시도해 보는 글을 작성하고자 합니다.
저는 ubuntu22.04, docker 24.0.2, MySql lastest 버전을 사용하였습니다.
1. 리플리케이션

데이터베이스의 리플리케이션은 마스터-슬레이브 구조를 가집니다. 마스터 데이터베이스는 쓰기 작업, 슬레이브 데이터베이스는 읽기 작업을 처리하는 방식입니다.
리플리케이션을 적용하면 다음의 장점을 가질 수 있습니다.
- 부하 분산: 리플리케이션은 슬레이브 서버가 읽기 요청, 마스터 서버가 쓰기 요청을 수행하므로 데이터베이스 부하를 줄일 수 있습니다.
- 고가용성: 마스터 데이터베이스에 문제가 생긴 경우, 슬레이브 서버는 상태를 유지하고 있으므로 데이터 손실의 위험성을 줄일 수 있습니다.
- 읽기 성능 향상: 슬레이브 데이터베이스는 독립적인 읽기 작업을 수행하므로, 읽기 성능을 향상할 수 있습니다.
하지만 고려해야 하는 상황은 다음과 같습니다.
- 쓰기 성능 이슈: 마스터 데이터베이스에 쓰기 요청을 수행한 후, 슬레이브 서버로 데이터를 업데이트하는 과정이 수반되므로, 쓰기 이슈가 발생할 수 있습니다.
구현 목적
1. 스케일 아웃:
수직적으로 서버의 사양을 높이는 것을 스케일 업이라고 한다면, 수평적으로 서버를 증설하는 방법을 스케일 아웃이라고 표현합니다. 스케일 아웃을 적용한다면 스케일 업 방식보다 갑자기 늘어나는 트래픽을 대웅하는데 유연한 구조를 가질 수 있습니다.
2. 데이터 백업:
DB서버에는 다양한 종류의 데이터가 저장이 됩니다. 이 과정에서 DB에 저장된 데이터들을 주기적으로 백업하는 것이 필수적입니다. 따라서, 데이터 백업의 절차등을 리플리케이션 서버에서 진행합니다.
3. 데이터 분석:
특정 데이터 집단에 대해 인사이트를 얻기 위해 분석용 쿼리등을 실행하기도 합니다. 이러한 분석용 쿼리는 대량의 데이터를 조회하는 경우가 많습니다. 집계 연산 등의 복잡하고 무거운 연산을 진행할 수 있으므로 복제를 사용해 여분의 레플리카 서버를 구축하기 위한 용도로도 사용합니다.
4. 데이터의 지리적 분산
서비스에서 사용되는 에플리케이션 서버와 DB는 지리적으로 근접하거나 멀 수 있습니다. DB 서버와 에플리케이션 서버의 거리에 따라 통신 시간이 달라질 수 있으므로 다양한 지점에 대한 DB 서버를 위치함으로써 응답 속도를 개선시킬 수 있습니다.
2. 리플리케이션 서버의 작동 원리
1) Binary Log, Replay Log 두 가지 메커니즘
MYSQL에서 데이터 복제는 Binary Log, Replay Log 두 가지 메커니즘으로 동작합니다.
Binary Log: 마스터 서버에 있는 바이너리 로그는 데이터 변경에 대한 정보를 기록합니다. 테이블에 새로운 데이터가 삽입되거나, 기존 데이터가 수정 또는 삭제될 때 정보를 기록합니다. 이 로그를 바탕으로 슬레이브 서버의 데이터를 업데이트합니다.
Relay Log: 슬레이브 서버는 마스터 서버에서 보낸 Binary Log를 기반으로 자신의 Relay Log에 저장합니다. 이 로그를 바탕으로 데이터를 업데이트합니다.
2) I/O 스레드, SQL 스레드
데이터 복제는 I/O 스레드와 SQL 스레드가 비동기적으로 작동하여 처리됩니다.
I/O 스레드(Slave I/O Thread): I/O 스레드는 슬레이브에서 실행되며 미스터 서버로부터 binary Log Events를 읽어오는 역할을 합니다. 마스터 서버의 Binary Log를 슬레이브의 Relay Log로 복사합니다.
SQL 스레드(Slave SQL Thread): SQL 스레드는 슬레이브에서 실행되며, I/O 스레드가 relay Log에 기록한 이벤트를 읽고 실행하는 역할을 수행합니다.
3) 특정 데이터 값 변경에 대한 Binary Log와 읽기 작업
MYSQL 복제에서 마스터의 Binary Log에서 슬레이브의 Relay Log로 데이터를 복제하는 I/O 스레드와 이를 실제 슬레이브 DB에서 적용하는 SQL 스레드는 비동기적으로 동작합니다.
I/O 스레드가 마스터의 Binary Log를 읽어 Relay Log에 기록하는 동안 Relay Log는 이전 이벤트를 읽어서 데이터를 업데이트할 수 있습니다. 이 과정에서 데이터 업데이트 간 지연이 발생한다면 최신 변경 사항이 적용되지 않은 데이터를 읽을 수 있습니다.
따라서, 만약 금전과 관련된 정보가 마스터 서버에는 업데이트되어 잔액 부족이 발생할 수 있지만, 지연 문제로 슬레이브 서버에는 잔액이 있다고 나올 수 있습니다. 따라서, 이러한 리플리카 서버의 형태는 마스터 서버에서 쓰기 작업을 수행하고, 리플리카 서버는 읽기 작업의 용도로 활용할 수 있습니다.
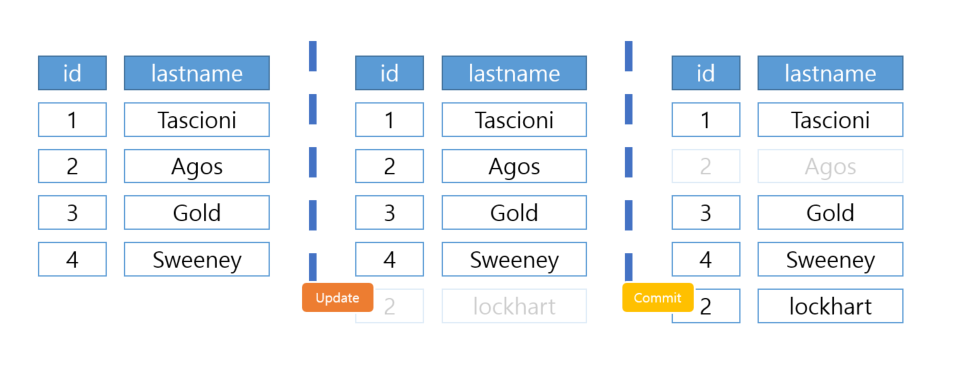
4) 슬레이브 서버는 커밋된 트랜잭션을 받아서 복제 처리
슬레이브 서버는 마스터 서버에서 커밋 혹은 롤백된 결과를 바탕으로 복제를 진행합니다. 즉, 마스터 서버에서는 커밋되지 않은 결과를 슬레이브 서버에 보내지 않음으로써 데이터의 원자성을 보존할 수 있습니다.
3. 마스터 서버와 슬레이브 서버 생성하기
마스터 서버와 슬레이브 서버를 서로 분리하기 위해 도커를 활용하여 마스터 서버, 슬레이브 서버를 분리하였습니다.
절차는 다음과 같습니다.
1) 도커로 마스터 서버 역할을 하는 mysql 컨테이너 생성
2) 마스터 서버에 database 생성 및 table 생성 후 dump.sql 생성
3) 마스터 서버에 연결할 슬레이브 mysql 서버 생성
4) 슬레이브 서버에 dump.sql 파일을 복제한 후, 마스터 서버에 슬레이브 연결
5) 마스터 서버에서 insert 한 결과가 슬레이브에 저장되는지 파악하기
1) 마스터 서버 도커파일 - mysql-master.dockerfile
FROM mysql:latest
ENV MYSQL_ROOT_PASSWORD root
ENV MYSQL_DATABASE sample
ENV MYSQL_USER user
ENV MYSQL_PASSWORD password
COPY my.cnf /etc/mysql/my.cnf
EXPOSE 3306
CMD ["mysqld"]
도커파일이 있는 폴더 내부에 my.cnf 파일을 추가하였습니다.
[mysqld]
log-bin=mysql-bin
server-id=1도커파일을 빌드하면 다음의 절차를 따르게 됩니다.
docker build -t mysql_master -f mysql-master.dockerfile .
도커 이미지가 생성되면, 도커 내부의 mysql 포트와 호스트 os의 포트를 연결하기 위해 다음의 커멘드를 입력합니다.
docker run -p 3307:3306 --name order_master -e MYSQL_ROOT_PASSWORD=1234 -d mysql-master
이후 도커 내부 쉘에 접속하기 위해 다음의 코드를 작성합니다.
docker exec -it order_master /bin/bash
# bash 이동 후
mysql -u root -p
password : 1234
# mysql 내부
CREATE USER 'orderroot'@'%' IDENTIFIED BY '1234';
ALTER USER 'orderroot'@'%' IDENTIFIED WITH mysql_native_password BY '1234';
GRANT REPLICATION SLAVE ON *.* TO 'orderroot'@'%';
FLUSH PRIVILEGES;
grant replcation slave on *.* to 'orderrot'@'%'; 은
사용자에게 복제(slave) 권한을 부여하는 구문입니다. 복제 권한은 마스터 서버에서 변경 사항을 읽을 수 있도록 허용하는 권한입니다. 이는 슬레이브 서버가 마스터 서버의 데이터 변경을 추적할 수 있게 합니다.
2) 데이터베이스 및 테이블 생성 후 dump.sql 생성
마스터 서버에서 데이터베이스 및 테이블을 생성하면 다음과 같습니다.
# mysql 쉘
create database orders;
CREATE TABLE member (
member_id BIGINT PRIMARY KEY,
name VARCHAR(255)
);
insert into member value (1, 'kose');
insert into member value (2, 'gose');
exit
# bash 쉘
mysqldump -u root -p orders < dump.sql;
ls // dump.sql이 있어야 함
exit
이어진 로컬의 쉘에서 다음의 명령어를 입력합니다.
docker cp order_master:dump.sql .
>> Successfully copied 3.58kB to /home/gosekose/.
3) 슬레이브 서버 생성하기
마스터 서버와 마찬가지로 도커파일을 생성하되(위에 있던 마스터 도커 파일과 동일합니다.)
my.cnf를 수정해서 빌드하여야 합니다.
[mysqld]
log-bin=mysql-bin
server-id=2
마스터 서버와 분리되는 고유한 id를 설정하기 위해 slave 서버는 server-id=2로 한 후 도커 빌드를 진행합니다.
docker build -t mysql_slave -f mysql-slave.dockerfile .
이어서 빌드가 완료되면 마스터 서버와 연결하기 위해 --link를 추가하여 다음의 명령어를 실행합니다.
--link는 서로 다른 컨테이너 간 연결을 돕는 도커 명령어입니다.
docker run -p 3308:3306 --name order_slave -e MYSQL_ROOT_PASSWORD=1234 --link order_master -d mysql-slave
4) 슬레이브 서버에 덤프 파일 적용
이전에 생성한 덤프파일을 도커로 복사한 후, (cp) 데이터 베이스를 생성하여 dump.sql을 복사합니다.
docker cp dump.sql order_slave:.
docker exec -it order_slave /bin/bash
mysql -u root -p
mysql> CREATE DATABASE orders;
mysql> exit
mysql -u root -p orders < dump.sql
기존에 있는 데이가 슬레이브에 덤프 되었습니다.
5) 슬레이브 서버에 마스터 서버 연결하기
order_master의 mysql로 이동한 후 현재 master 서버의 status를 확인합니다.
mysql> SHOW MASTER STATUS\G
여기서 기억할 부분은 mysql-bin.000003, position 2193입니다.
이어서 슬레이브 서버의 order_slave의 mysql로 이동하여 마스터 서버를 연결합니다.
CHANGE MASTER TO MASTER_HOST='order_master', MASTER_USER='orderroot', MASTER_PASSWORD='1234', MASTER_LOG_FILE='mysql-bin.000003', MASTER_LOG_POS=2193;
마스터 서버가 연결된 것을 확인하기 위해 하단의 명령어를 입력합니다.
SHOW SLAVE STATUS\G
Master_LOG_FILE 및 Read_Master_Log_Pos가 모두 마스터 서버의 값이 잘 기입되었습니다.
하단에 SlaveI_IO_Running, Slave_SQL_Running이 모두 Yes가 떠야 성공입니다.
이는 위에서 설명했던 슬레이브 서버에서 작용하는 스레드 두 가지가 모두 완료되어야 하는 것을 의미합니다.
5) 마스터 서버에 쓰기 진행
마스터 서버에 새로운 member를 저장합니다.
insert into member value(3, 'gosekose');
마스터 서버

슬레이브 서버

값이 잘 저장된 것을 확인할 수 있습니다.
이번 포스팅은 MySQL 리플리카 서버를 적용하는 과정에 대한 글을 작성하였습니다. 다음 글은 리플리카 서버를 바탕으로 스프링 부트 서버를 기동하여 리플리카 서버를 활용하는 글을 작성하고자 합니다. 이상으로 포스팅을 마치도록 하겠습니다. 감사합니다!
사진 출처: https://tgyun615.com/118
참고 자료: https://escapefromcoding.tistory.com/710
'DB' 카테고리의 다른 글
| [DB] 락(잠금) (0) | 2023.04.24 |
|---|---|
| [DB] MySQL8.0 Index (0) | 2023.02.06 |
| [DB] MySQL 엔진 아키텍처 (Real MySQL 8.0) (0) | 2023.01.22 |
| [DB] MySQL 계정 생성 및 권한 부여 (Real MySQL 8.0) (0) | 2023.01.07 |
| [DB] 칼럼형 DBMS VS 로우형 DBMS (0) | 2022.12.28 |