안녕하세요. 회사와 함께 성장하고 싶은 KOSE입니다.
이번 포스팅은 마이크로 서비스 패턴 5장 - 비즈니스 로직 설계 정리를 작성하고자 합니다.
해당 챕터는 애그리거트라는 개념으로 비즈니스 로직을 설계하는 과정을 설명하고 있습니다.
JPA 등을 활용한 객체지향적인 개발은 MSA에서 복잡성을 야기할 수 있기에,
애그리거트를 활용한 도메인 이벤트 발행을 통해 느슨한 결합을 유지하며 비즈니스 로직을 처리할 수 있습니다.
예제는 제가 작성한 예제로 책의 내용과 다를 수 있습니다!
1. 애그리거트란?
애그리거트
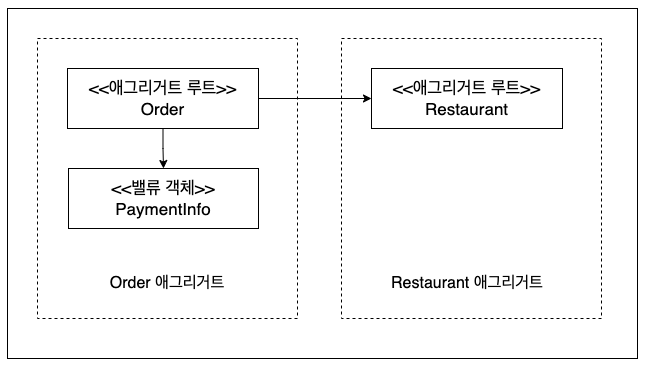
- 애그리거트는 연관된 객체들의 집합을 의미하며, 해당 집합의 데이터 무결성을 일관성 경계 내에서 보장하기 위한 설계 패턴입니다.
- 주문 애그리거트는 주문, 주문 항목 등으로 구성될 수 있습니다.
애그리거트 루트
- 애그리거트의 집합 중에서 외부와의 통신을 담당하는 주요 객체를 의미합니다.
- 애그리거트 루트는 애그리거트 내의 다른 객체들을 직접 참조할 수 있지만, 애그리거트 밖에서는 애그리거트 루트만을 참조해야 합니다.
- 주문이 주문 애그리거트의 루트라면, 외부에서 주문 항목을 직접 참조하는 것은 허용되지 않습니다 (캡슐화)
애그리거트는 연관된 객체를 일관성 있는 경계 내에서 보장하도록 설계합니다.
즉, 경계가 분명하여 연관성이 적은 객체는 느슨하게 유지한다는 의미입니다.
애그리거트를 유지하려면 적용해야 하는 규칙이 있습니다.
2. 애그리거트 규칙
1) 애그리거트 루트만 참조하라.
- 외부 클래스는 반드시 애그리거트의 루트 엔티티만 참조할 수 있도록 제한해야 합니다.
- 가령 어떤 서비스가 리포지토리를 통해 DB에서 애그리거트를 로드하고 애그리거트의 루트 래퍼런스를 얻고자 하면,
애그리거트 루트에 있는 메서드를 호출하여 애그리거트를 업데이트해야 합니다.

애그리거트를 수정해야 할 때, 애그리거트 루트를 통해 수정해야 객체의 캡슐화를 지킬 수 있습니다.
PaymentInfo는 Order의 애그리거트에 속하는 객체입니다.
PaymentInfo를 임의로 수정한다면, 이를 참조하는 객체들의 불변성이 깨져 데이터의 정합성이 맞지 않을 수 있습니다.
따라서, Order의 내부 함수를 통해 Order의 객체 값을 변경하는 방법을 채택할 수 있습니다.
2) 애그리거트 각 참조는 반드시 기본키를 사용하라.
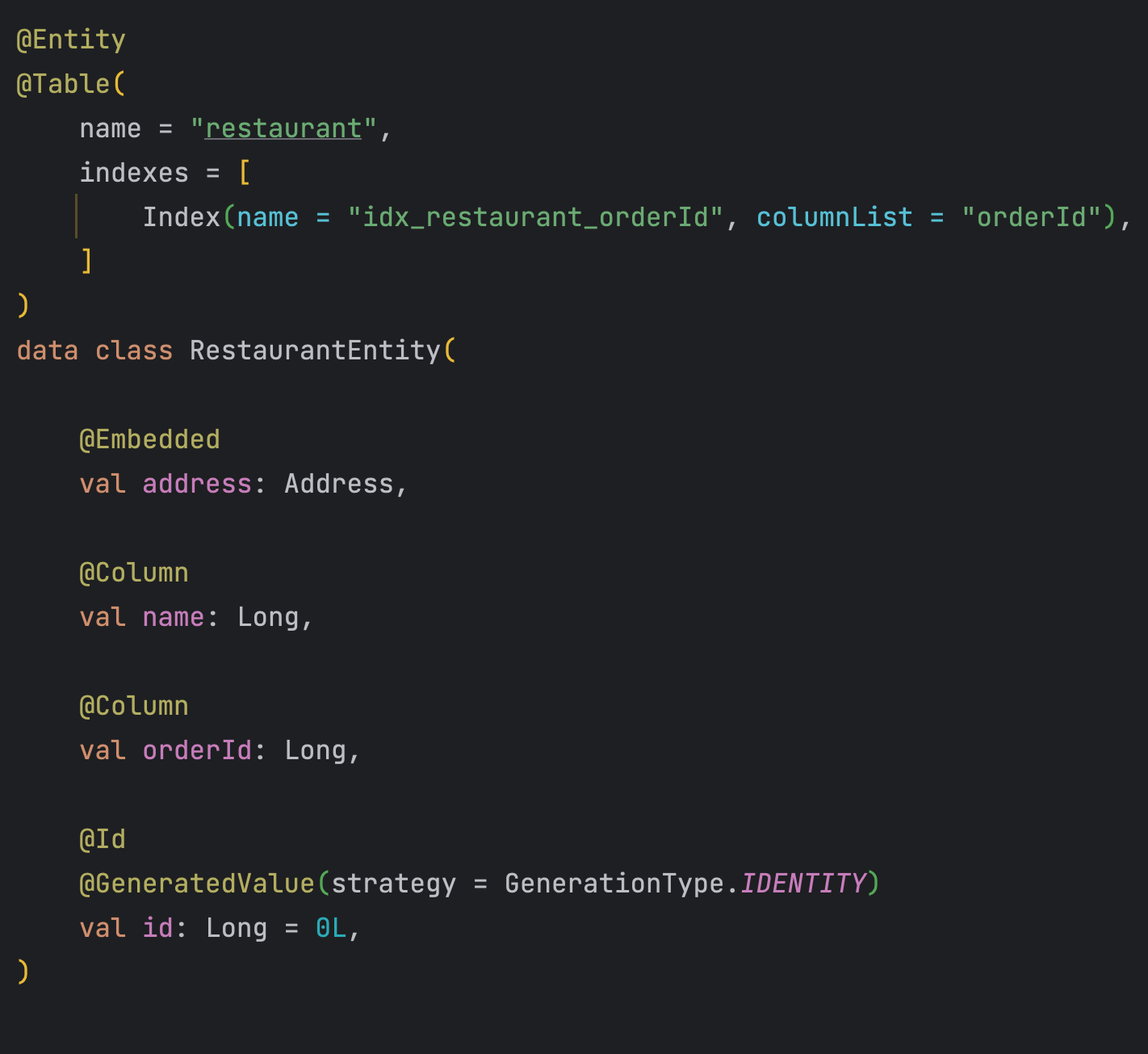
- 애그리거트는 객체 래퍼런스 대신 신원으로 서로를 참조해야 합니다.

Restaurant는 order 자체의 객체 레퍼런스 참조가 아닌, orderId라는 식별자를 통해 간접 참조 하고 있습니다.
이렇게 식별자를 통한 참조는 느슨한 결합을 유지할 수 있습니다.
그 이유는 다음과 같습니다.
MSA는 각 서비스에 특화적인 데이터베이스 테이블을 가지고 있습니다.
만약 레스토랑 서비스와 주문 서비스가 분리되어 있다면, 레스토랑 서비스는 주문에 대한 테이블은 따로 가지고 있지 않을 수 있습니다.
따라서, 객체 자체의 참조를 설정하게 된다면 복잡성이 커질 수 있습니다.
위 코드처럼 해당 도메인의 엔티티는 orderId를 참조가 아닌 객체 식별자로 가짐으로써,
Lazy 조인 혹은 fetch 조인 등 다른 객체의 참조에 의존하지 않고 필요한 객체만 DB로부터 가져올 수 있습니다.
만약 객체의 식별자가 아닌 객체 자체의 참조를 사용한다면,
외부 서비스로부터 order를 가져와야 하는 경우, order에 대한 정보를 가져온 후 이를 객체화하는 작업이 수행되어야 할 것입니다.
3) 하나의 트랜잭션으로 하나의 애그리거트를 생성/수정하라
주문이라는 트랜잭션을 처리하면, 각 마이크로서비스별로 로컬 트랜잭션을 적용합니다.
이에 따라, 계속 요청을 수행하거나 요청을 중단하고 보상 트랜잭션을 처리하는 과정이 수행될 수 있습니다.
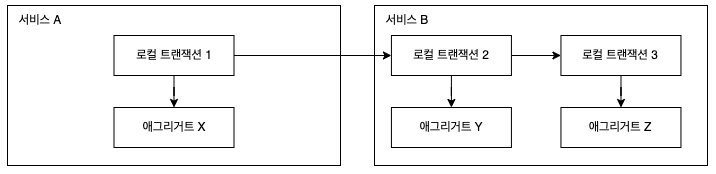
애그리거트를 이용한다면 이러한 사가패턴의 라이프사이클에 맞춰서 트랜잭션을 처리할 수 있습니다.
서비스 A는 애그리거트 X를 로컬 트랜잭션 1에서 처리하고, 이벤트를 발행합니다.
서비스 B는 서비스 A의 이벤트를 수신하고 애그리거트 Y를 로컬 트랜잭션 2에서 처리하고 이벤트를 발행합니다.
이러한 방식으로 사가패턴을 적용하여 하나의 트랜잭션에서 하나의 애그리거트를 처리할 수 있습니다.
3. 도메인 이벤트 발행
DDD 맥락에서 도메인 이벤트는 애그리거트에 발생한 사건입니다.
Order가 애그리거트라면 주문 생성, 주문 취소, 주문 배달 등 상태가 바뀌는 이벤트가 발생합니다.
애그리거트의 상태가 전이될 때마다 이에 관련된 컨슈머를 위해 적절한 이벤트를 발행합니다.
이벤트는 발행의 이벤트를 표현하는 id, type, 그리고 발행에 필요한 객체 등을 추가로 넣을 수 있습니다.

이벤트 강화
주문 결제 생성 이벤트를 수신할 때, 결제 내역이 필요할 수 있습니다.
이벤트에 결제 내역이 존재하지 않는다면, 주문 서비스 혹은 결제 서비스로 결제 내역에 대한 요청을 다시 수행해야 합니다.
이러한 문제를 방지하고자, 이벤트 발생 시에 수신자에게 필요한 정보를 제공하는 것이 이벤트 강화 방식입니다.

앞 서 구현한 OrderPaymentCreationPublishEvent는 필요한 결제 내역등을 이벤트로 제공하고 있습니다.
컨슈머는 이벤트 메시지 형태로 이벤트를 수신하고 필요한 이벤트를 T 타입으로 정의한 message로부터 얻을 수 있습니다.
이처럼 이벤트 강화 방식에 제네릭을 활용한다면 확장성이 높아지고, 이벤트를 발행한 서비스를 다시 쿼리 해서 데이터를 가져올 필요가 없으므로 이벤트 컨슈머가 간단해질 수 있습니다.
4. 도메인 이벤트 생성 및 발행
도메인 이벤트를 이용한 통신은 비동기 메세징 형태를 취하지만,
비즈니스 로직이 도메인 이벤트를 메시지 브로커에 발행하려면 먼저 도메인 이벤트를 생성해야 합니다.
도메인 이벤트 생성
도메인 이벤트는 애그리거트가 발행합니다. 애그리거트가 도메인 이벤트를 발행함으로써, 애그리거트의 경계를 명확하게 하고, 하나의 애그리거트 (예시로 주문)의 책임을 명확하게 분리할 수 있습니다. 이 도메인을 활용하는 application 계층이나 api 계층은 이를 호출하는 방법으로 의존관계 주입을 받을 수 있습니다.

도메인의 유즈케이스에 속하는 애그리거트는 createOrder()로 주문을 생성하고,
createOrderUserPublishEvent()라는 함수를 호출하여 orderUserEvent를 생성합니다.
이어서, orderUserPublishEventHander를 호출하여 이벤트를 처리하는 process 함수를 호출합니다.
이 함수는 실제 이벤트를 발행하는 역할을 수행합니다.
5. 도메인 이벤트 소비
도메인 이벤트는 메시지로 바뀌어 아파치 카프카 같은 메세지 브로커에 발행됩니다.
카프카 컨슈머는 메세지로 바뀐 이벤트를 수신하고, 이를 디스패처로 넘깁니다.

디스패처는 이벤트의 타입을 메시지의 메타데이터를 통해 식별하여 적절하게 캐스팅한 후
필요한 이벤트 핸들러로 위임할 수 있습니다.
현재 저는 이벤트 강화 방식을 적용하였기 때문에 캐스팅하는 과정에서 어떠한 클래스로 캐스팅이 필요한지 메타데이터를
JSON으로 직렬화하는 과정에 추가하였습니다.
이를 통해 카프카 컨슈머는 @Payload에 있는 message를 수신할 때 적절한 타입으로 캐스팅할 수 있었습니다.

6. 정리하며!
애그리거트는 도메인 모델을 모듈화 하고, 서비스 간 객체 참조 가능성을 배제하며,
전체 ACID 트랜잭션을 서비스 내부에 국한시키므로 유용하게 사용할 수 있습니다.
실제 사가패턴을 적용하는 코드를 작성했을 때, 이러한 애그리거트 패턴이 익숙하지 않았습니다.
어느 단계까지 해당 서비스의 애그리거트로 정의할 것인지, 한 번의 이벤트에 어떠한 정보까지 제공해주어야 하는지 등
많은 고민을 하며 코드를 작성했습니다.
해당 개념을 읽고 나서 다시 코드를 보니,
그 당시에 고민했었던 내용이 애그리거트의 경계와 이벤트 강화 방식이었음을 알게 되었습니다.!
다음 챕터는 이벤트 소싱을 적용하는 챕터입니다!
다음 장도 너무 기대됩니다~!
읽어주셔서 감사합니다!
'Architecture' 카테고리의 다른 글
| [Architecture] 디자인 패턴 - 전략 패턴 (0) | 2022.12.29 |
|---|







