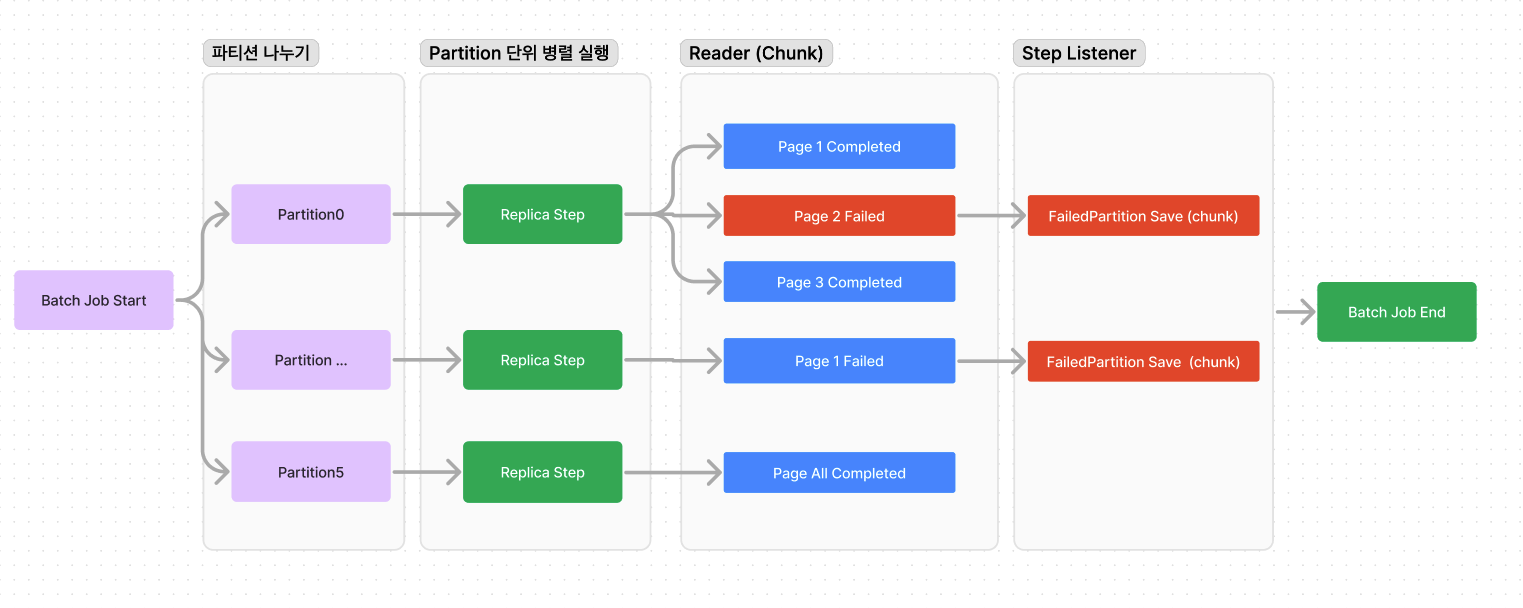
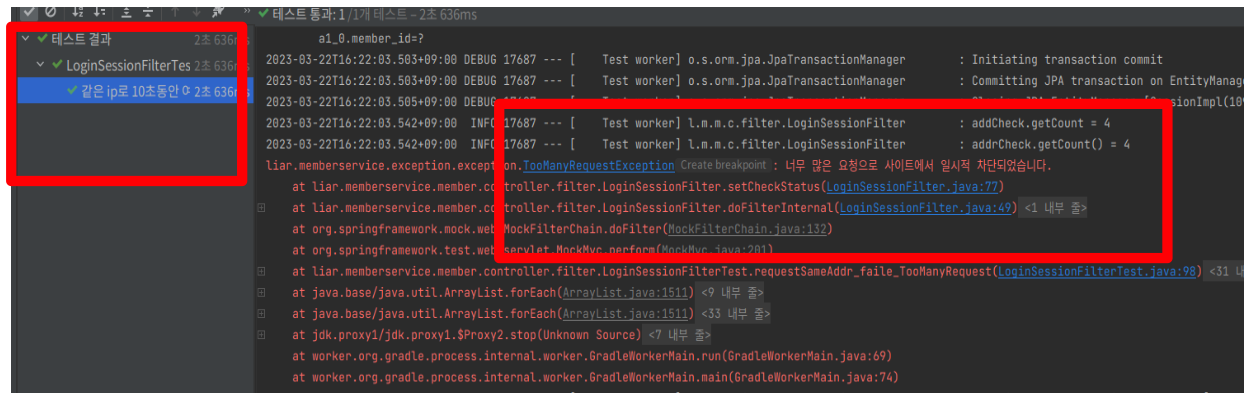
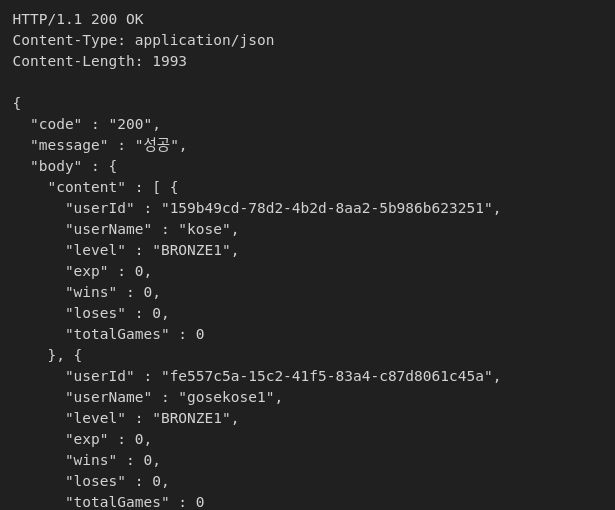
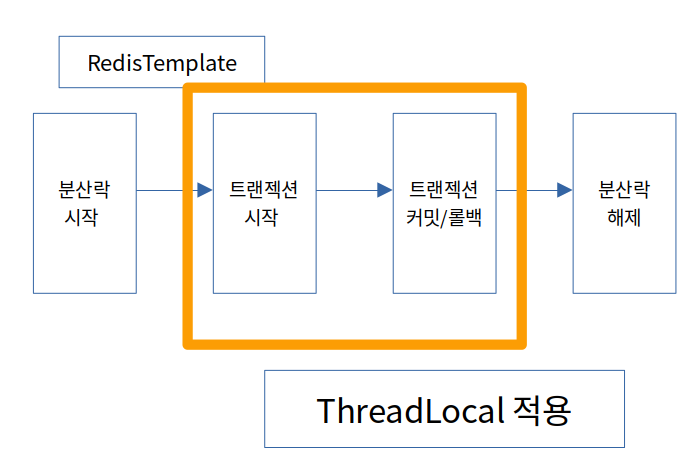
안녕하세요. CircuitBreaker, Cache, 외부 스토리지를 활용하여 첨부파일 관리하는 과정을 작성하도록 하겠습니다. 1. 목표 시나리오 첨부파일을 업로드할 때, 두 가지 주요 방법이 있습니다:Client -> Server로 MultipartFile을 업로드:이 방법은 클라이언트가 파일을 서버로 전송하고, 서버가 이 파일을 스토리지에 저장합니다.장점: 서버가 파일 업로드와 저장을 관리하므로 보안과 검증이 용이합니다.단점: 서버에 부하가 증가하고, 대규모 파일 업로드 시 성능 문제가 발생할 수 있습니다.클라이언트가 직접 스토리지에 파일을 업로드:클라이언트가 직접 외부 스토리지에 파일을 업로드합니다.장점: 서버 부하를 줄일 수 있으며, 클라이언트가 직접 스토리지에 접근하여 빠른 업로드가 가능합니다..